Seata简介
Seata的前身是阿里巴巴集团内大规模使用保证分布式事务一致性的中间件,Seata是其开源产品,由社区维护。在介绍Seata前,先与大家讨论下我们业务发展过程中经常遇到的一些问题场景。
业务场景
我们业务在发展的过程中,基本上都是从一个简单的应用,逐渐过渡到规模庞大、业务复杂的应用。这些复杂的场景难免遇到分布式事务管理问题,Seata的出现正是解决这些分布式场景下的事务管理问题。介绍下其中几个经典的场景:
场景一:分库分表场景下的分布式事务
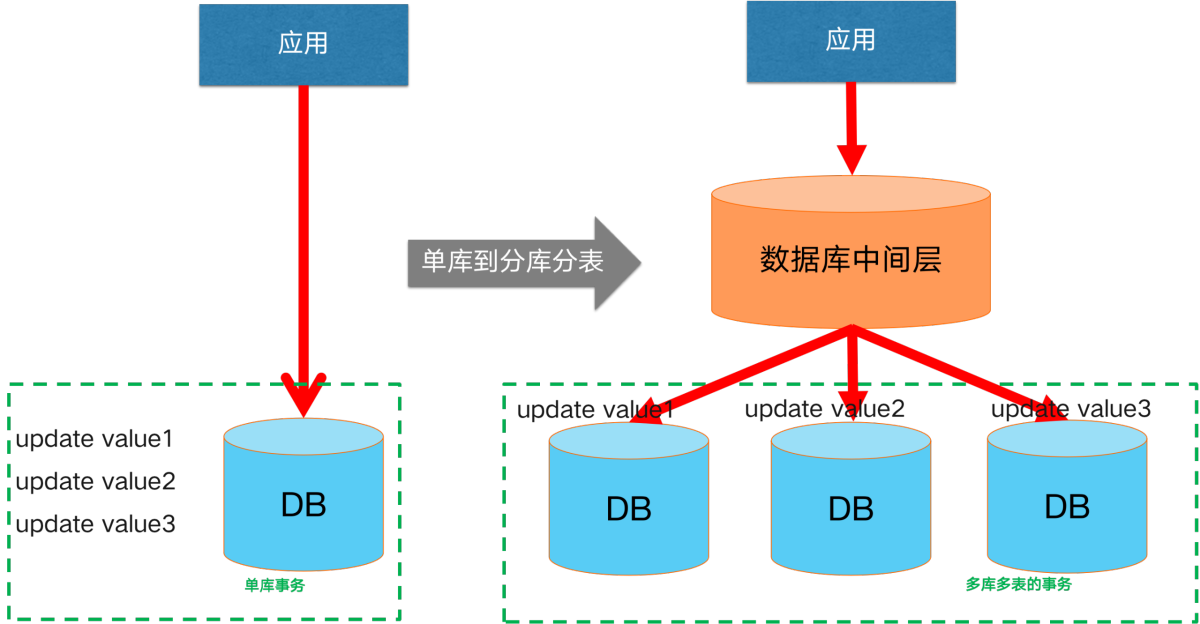 起初我们的业务规模小、轻量化,单一数据库就能保障我们的数据链路。但随着业务规模不断扩大、业务不断复杂化,通常单一数据库在容量、性能上会遭遇瓶颈。通常的解决方案是向分库、分表的架构��演进。此时,即引入了分库分表场景下的分布式事务场景。
起初我们的业务规模小、轻量化,单一数据库就能保障我们的数据链路。但随着业务规模不断扩大、业务不断复杂化,通常单一数据库在容量、性能上会遭遇瓶颈。通常的解决方案是向分库、分表的架构��演进。此时,即引入了分库分表场景下的分布式事务场景。
场景二:跨服务场景下的分布式事务
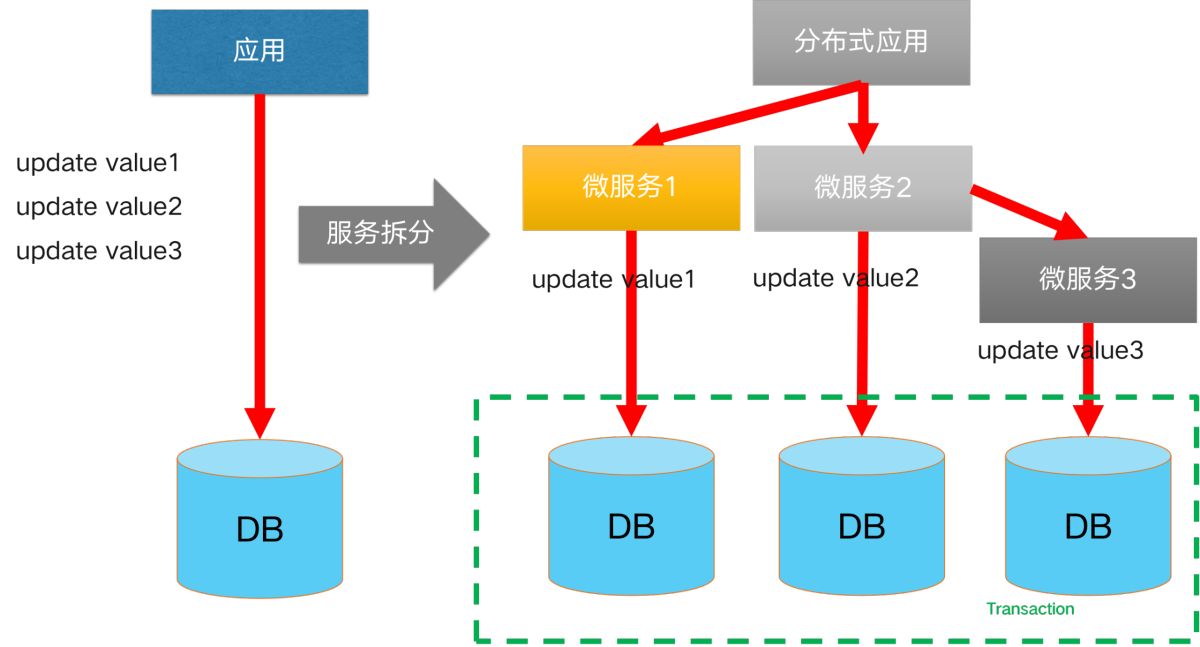 降低单体应用复杂度的方案:应用微服务化拆分。拆分后,我们的产品由多个功能各异的微服务组件构成,每个微服务都使用独立的数据库资源。在涉及到跨服务调用的数据一致性场景时,就引入了跨服务场景下的分布式事务。
降低单体应用复杂度的方案:应用微服务化拆分。拆分后,我们的产品由多个功能各异的微服务组件构成,每个微服务都使用独立的数据库资源。在涉及到跨服务调用的数据一致性场景时,就引入了跨服务场景下的分布式事务。
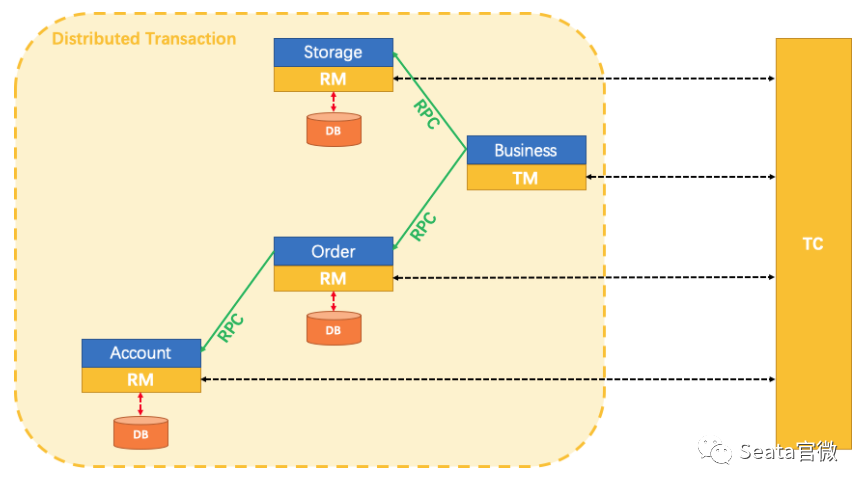
Seata架构
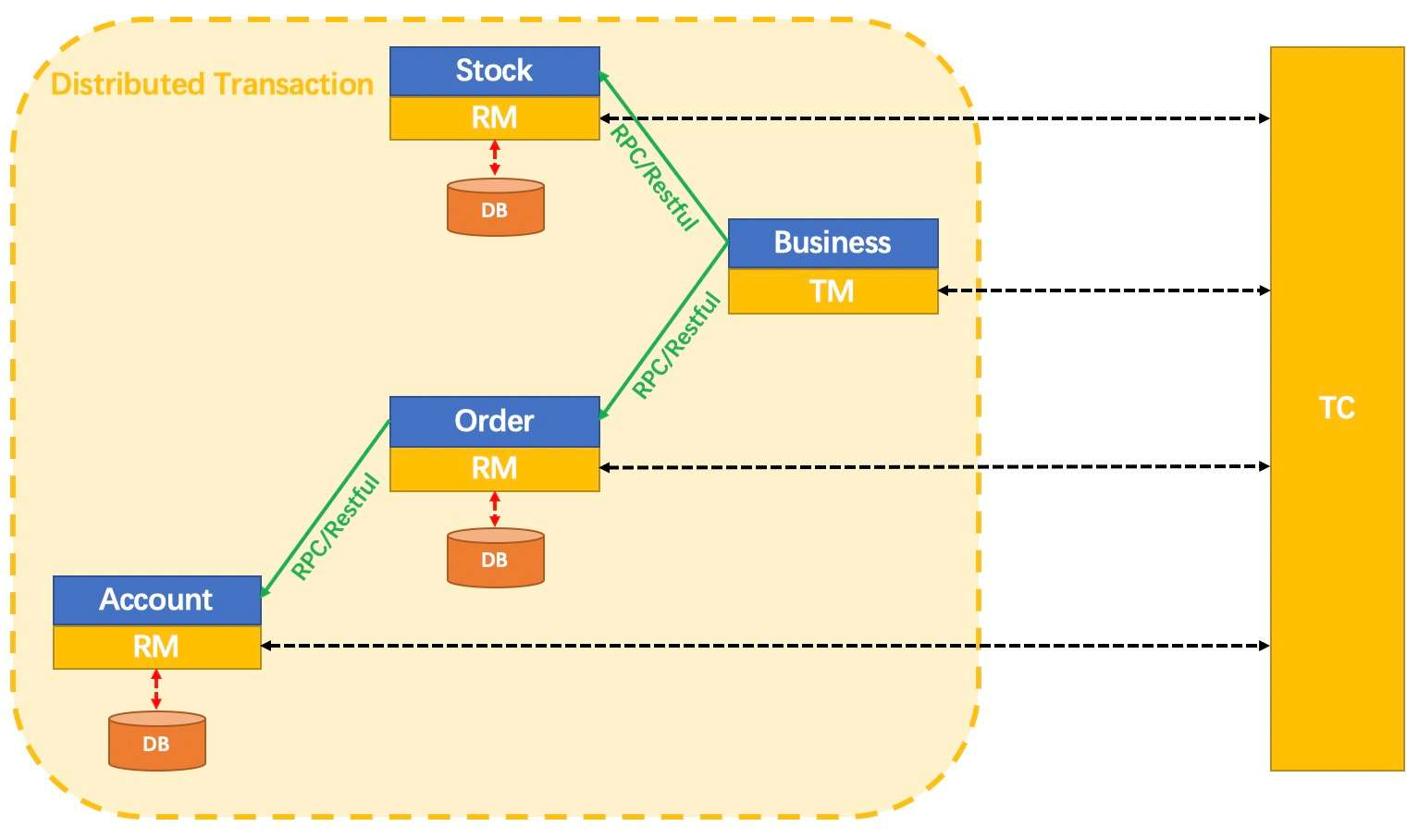 其核心组件主要如下:
其核心组件主要如下:
- Transaction Coordinator(TC)
事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
- Transaction Manager(TM)
控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议,TM定义全局事务的边界。
- Resource Manager(RM)
控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和��回滚。RM负责定义分支事务的边界和行为。
Seata的可观测实践
为什么需要可观测?
- 分布式事务消息链路较复杂
Seata在解决了用户易用性和分布式事务一致性这些问题的同时,需要多次TC与TM、RM之间的交互,尤其当微服务的链路变复杂时,Seata的交互链路也会呈正相关性增加。这种情况下,其实我们就需要引入可观测的能力来观察、分析事物链路。
- 异常链路、故障排查难定位,性能优化无从下手
在排查Seata的异常事务链路时,传统的方法需要看日志,这样检索起来比较麻烦。在引入可观测能力后,帮助我们直观的分析链路,快速定位问题;为优化耗时的事务链路提供依据。
- 可视化、数据可量化
可视化能力可让用户对事务执行情况有直观的感受;借助可量化的数据,可帮助用户评估资源消耗、规划预算。
可观测能力概览
| 可观测维度 | seata期望的能力 | 技术选型参考 |
|---|---|---|
| Metrics | 功能层面:可按业务分组��隔离,采集事务总量、耗时等重要指标 | |
| 性能层面:高度量性能,插件按需加载 | ||
| 架构层面:减少第三方依赖,服务端、客户端能够采用统一的架构,减少技术复杂度 | ||
| 兼容性层面:至少兼容Prometheus生态 | Prometheus:指标存储和查询等领域有着业界领先的地位 | |
| OpenTelemetry:可观测数据采集和规范的事实标准。但自身并不负责数据的存储,展示和分析 | ||
| Tracing | 功能层面:全链路追踪分布式事务生命周期,反应分布式事务执行性能消耗 | |
| 易用性方面:对使用seata的用户而言简单易接入 | SkyWalking:利用Java的Agent探针技术,效率高,简单易用。 | |
| Logging | 功能层面:记录服务端、客户端全部生命周期信息 | |
| 易用性层面:能根据XID快速匹配全局事务对应链路日志 | Alibaba Cloud Service | |
| ELK |
Metrics维度
设计思路
- Seata作为一个被集成的数据一致性框架,Metrics模块将尽可能少的使用第三方依赖以降低发生冲突的风险
- Metrics模块将竭力争取更高的度量性能和更低的资源开销,尽可能降低开启后带来的副作用
- 配置时,Metrics是否激活、数据如何发布,取决于对应的配置;开启配置则自动启用,并默认将��度量数据通过prometheusexporter的形式发布
- 不使用Spring,使用SPI(Service Provider Interface)加载扩展
模块设计
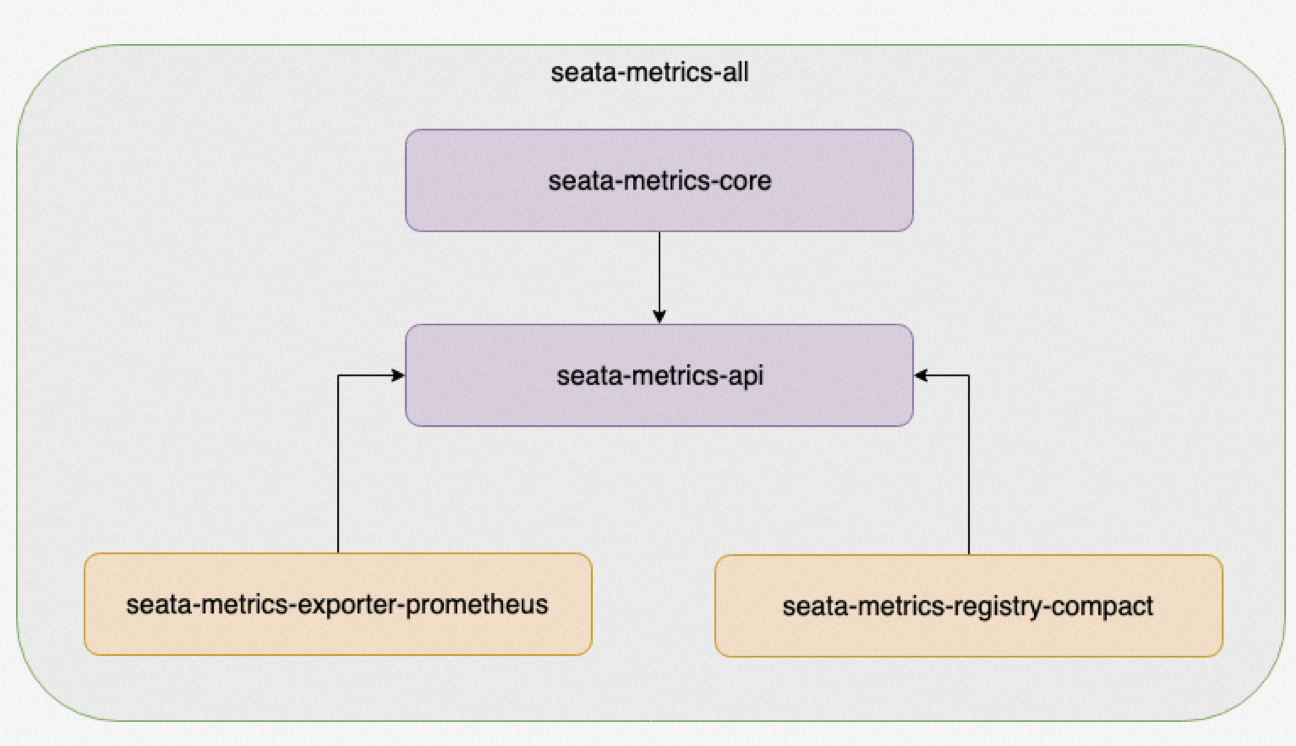
- seata-metrics-core:Metrics核心模块,根据配置组织(加载)1个Registry和N个Exporter;
- seata-metrics-api:定义了Meter指标接口,Registry指标注册中心接口;
- seata-metrics-exporter-prometheus:内置的prometheus-exporter实现;
- seata-metrics-registry-compact:内置的Registry实现,并轻量级实现了Gauge、Counter、Summay、Timer指标;
metrics模块工作流
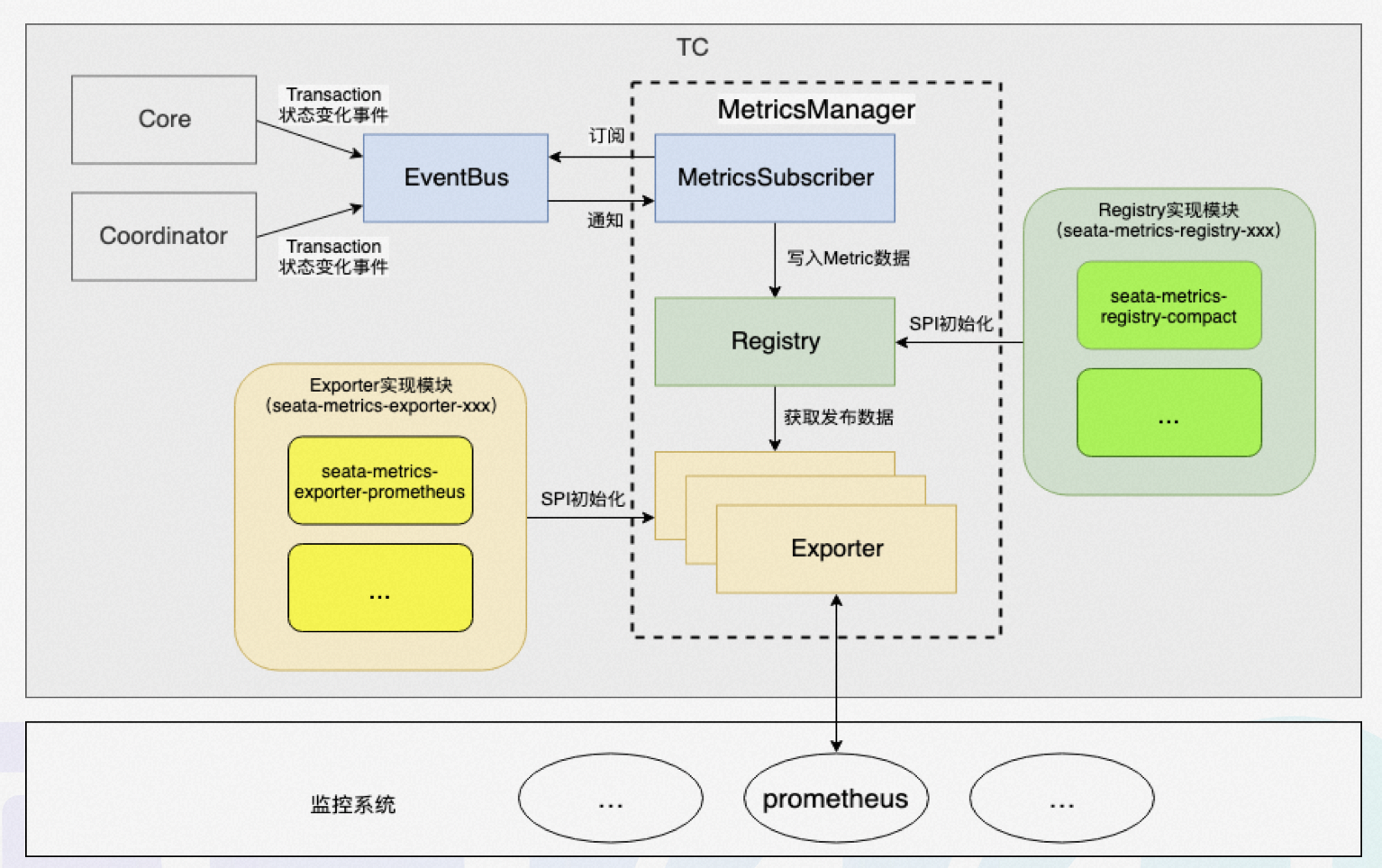 上图是metrics模块的工作流,其工作流程如下:
上图是metrics模块的工作流,其工作流程如下:
- 利用SPI机制,根据配置加载Exporter和Registry的实现类;
- 基于消息订阅与通知机制,监听所有全局事务的状态变更事件,并publish到EventBus;
- 事件订阅者消费事件,并将生成的metrics写入Registry;
- 监控系统(如prometheus)从Exporter中拉取数据。
TC核心指标

TM核心指标
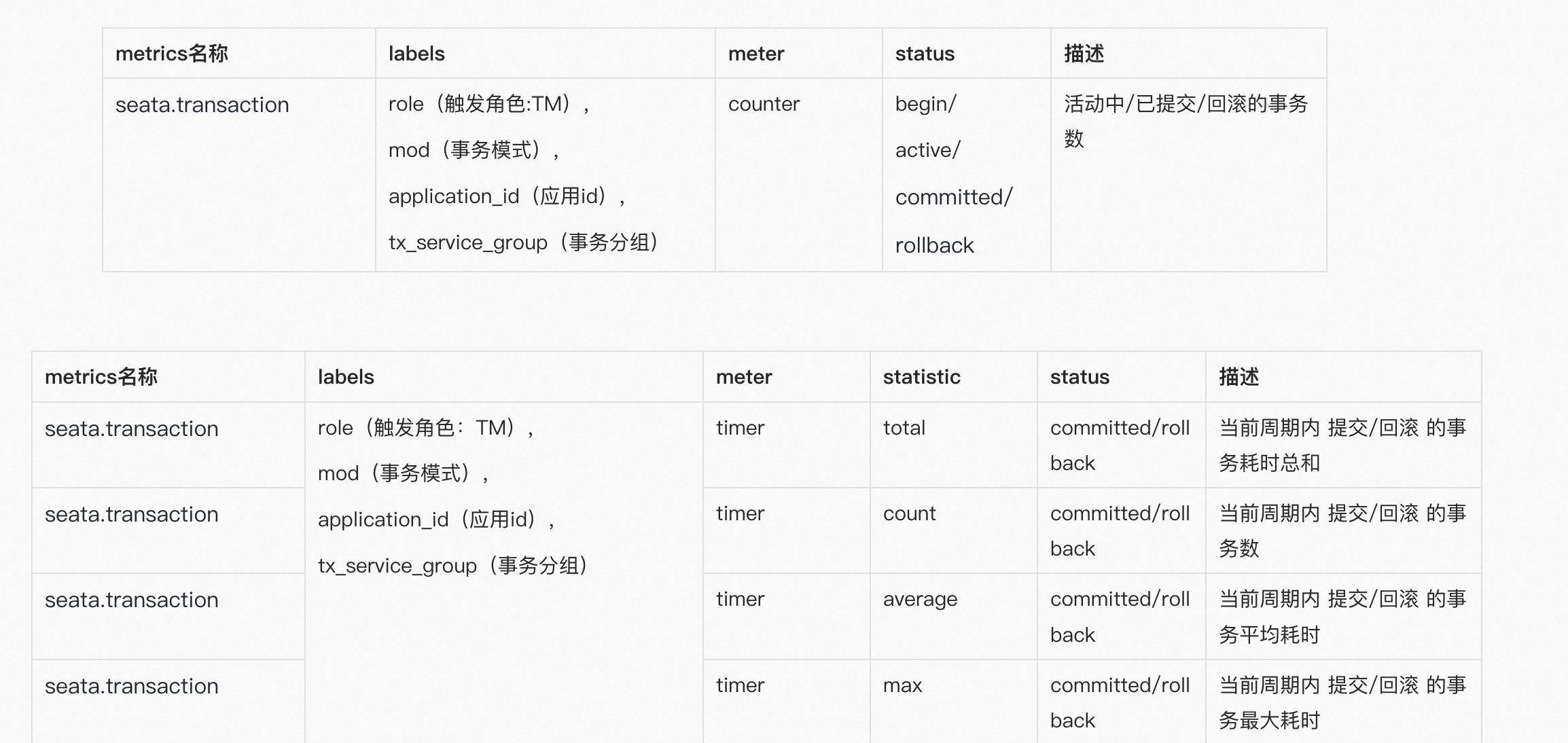
RM核心指标

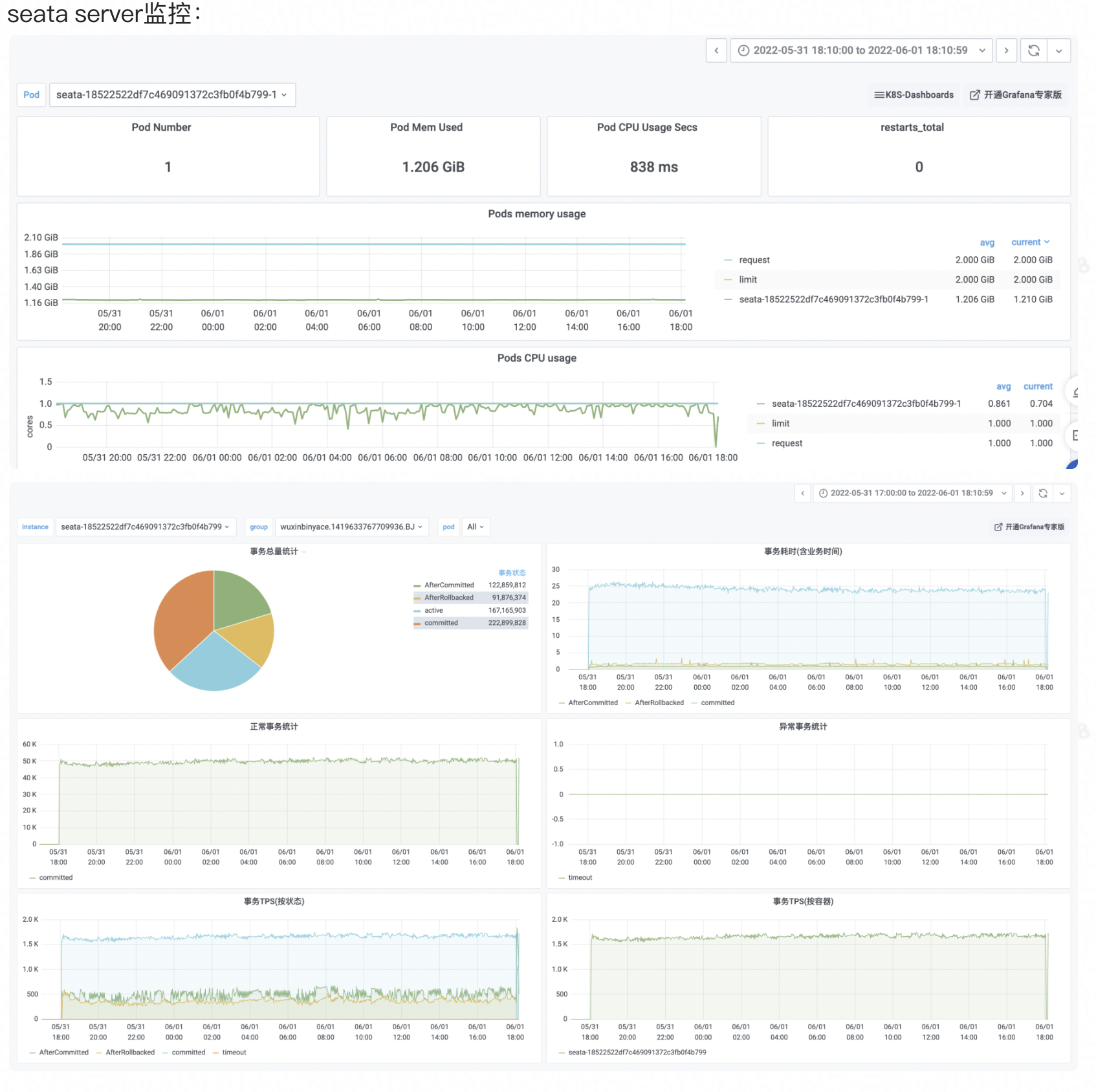
大盘展示
Tracing维度
Seata为什么需要tracing?
- 对业务侧而言,引入Seata后,对��业务性能会带来多大损耗?主要时间消耗在什么地方?如何针对性的优化业务逻辑?这些都是未知的。
- Seata的所有消息记录都通过日志持久化落盘,但对不了解Seata的用户而言,日志非常不友好。能否通过接入Tracing,提升事务链路排查效率?
- 对于新手用户,可通过Tracing记录,快速了解seata的工作原理,降低seata使用门槛。
Seata的tracing解决方案
- Seata在自定义的RPC消息协议中定义了Header信息;
- SkyWalking拦截指定的RPC消息,并注入tracing相关的span信息;
- 以RPC消息的发出&接收为临界点,定义了span的生命周期范围。
基于上述的方式,Seata实现了事务全链路的tracing,具体接入可参考为[Seata应用 | Seata-server]接入Skywalking。
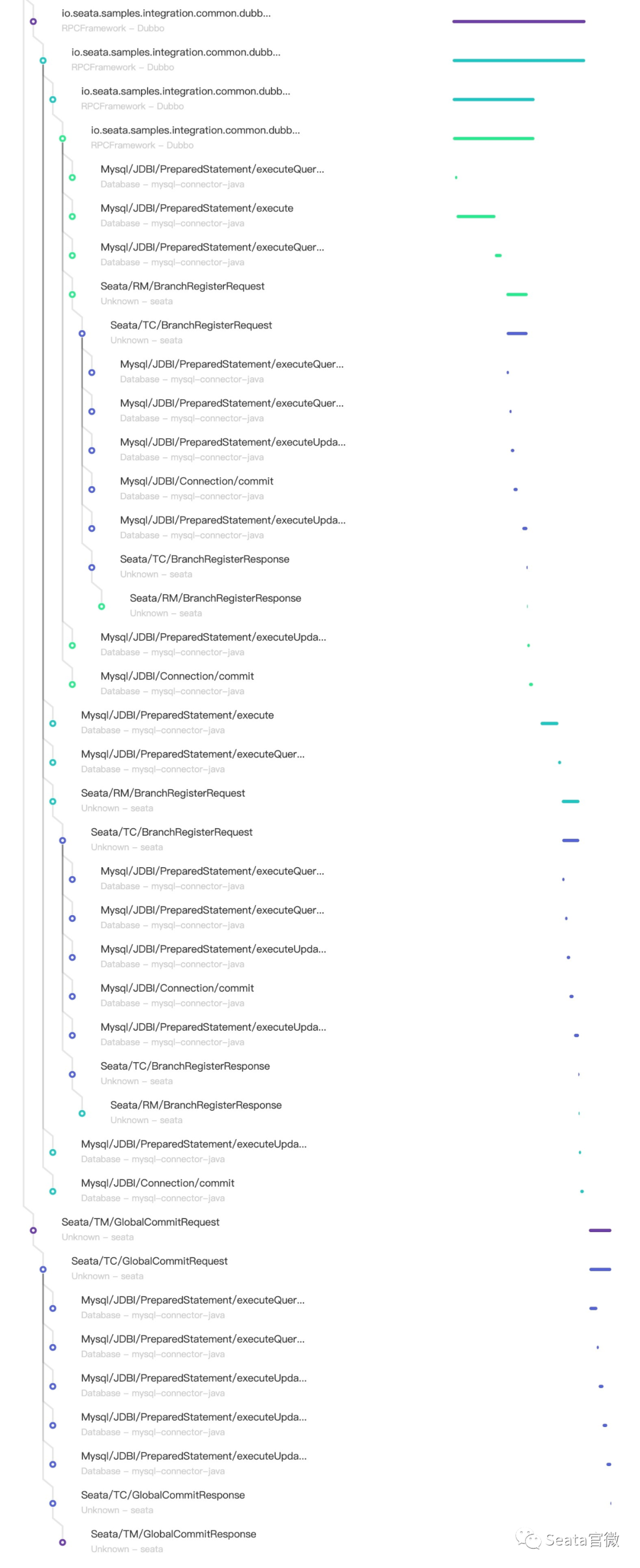
tracing效果
- 基于的demo场景:
- 用户请求交易服务
- 交易服务锁定库存
- 交易服务创建账单
- 账单服务进行扣款
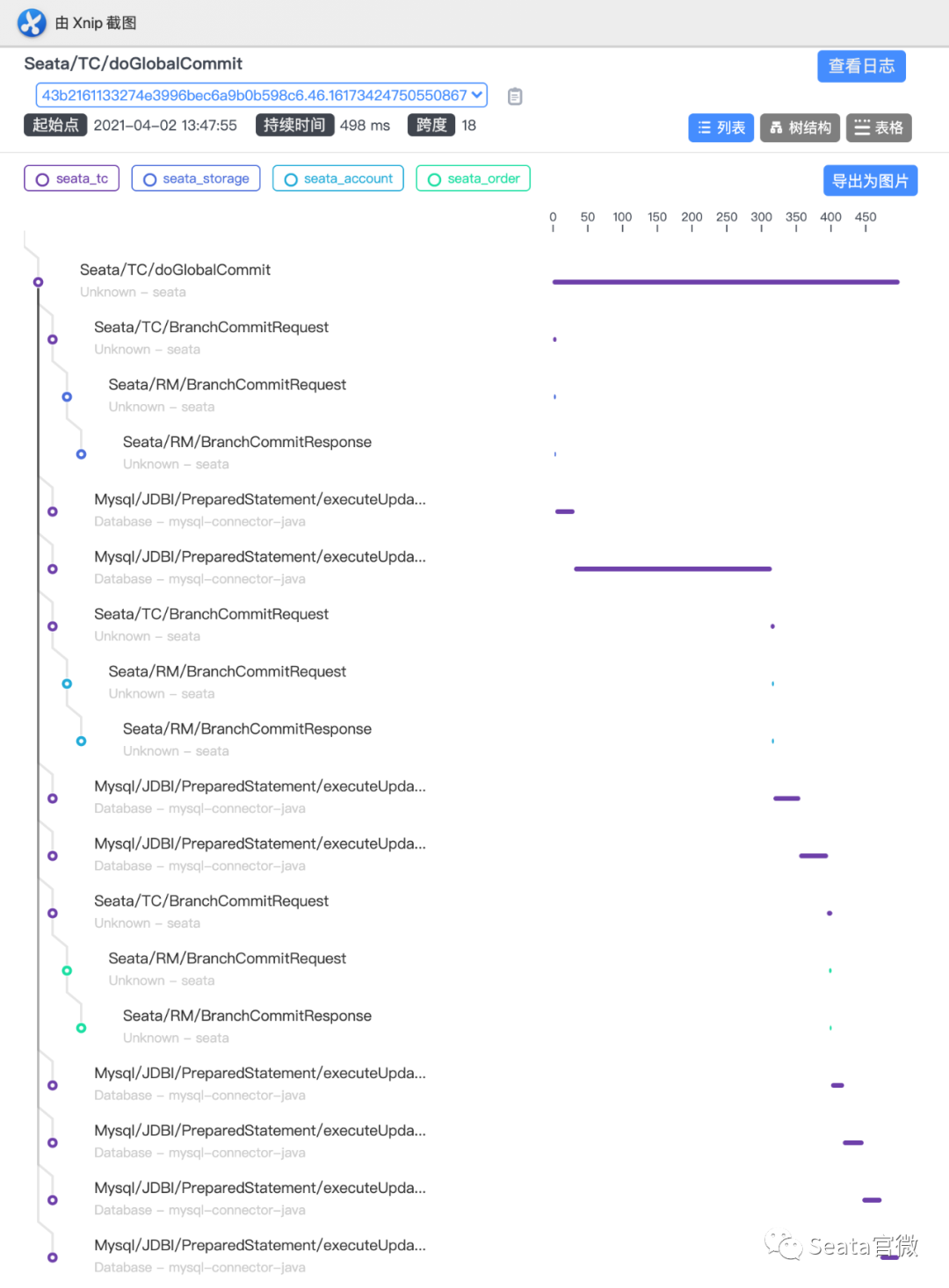
- GlobalCommit成功的事务链路(事例)

Logging维度
设计思路
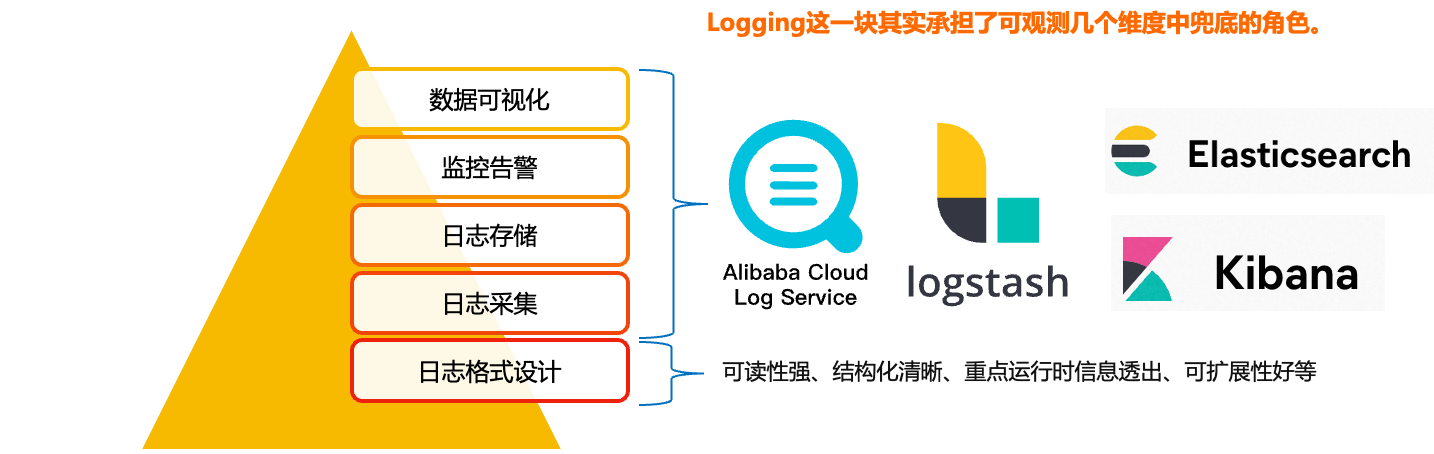 Logging这一块其实承担的是可观测这几个维度当中的兜底角色。放在最底层的,其实就是我们日志格式的设计,只有好日志格式,我们才能对它进行更好的采集、模块化的存储和展示。在其之上,是日志的采集、存储、监控、告警、数据可视化,这些模块更多的是有现成的工具,比如阿里的SLS日志服务、还有ELK的一套技术栈,我们更多是将开销成本、接入复杂度、生态繁荣度等作为考量。
Logging这一块其实承担的是可观测这几个维度当中的兜底角色。放在最底层的,其实就是我们日志格式的设计,只有好日志格式,我们才能对它进行更好的采集、模块化的存储和展示。在其之上,是日志的采集、存储、监控、告警、数据可视化,这些模块更多的是有现成的工具,比如阿里的SLS日志服务、还有ELK的一套技术栈,我们更多是将开销成本、接入复杂度、生态繁荣度等作为考量。
日志格式设计
这里拿Seata-Server的一个日志格式作为案例:
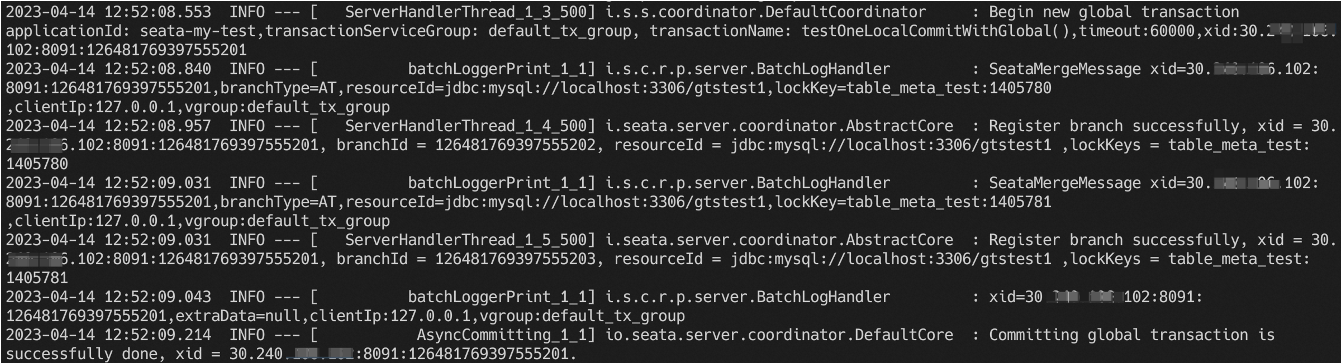
- 线程池规范命名:当线程池、线程比较多时,规范的线程命名能将无序执行的线程执行次序清晰展示。
- 方法全类名可追溯:快速定位到具体的代码块。
- 重点运行时信息透出:重点突出关键日志,不关键的日志不打印,减少日志冗余。
- 消息格式可扩展:通过扩展消息类的输出格式,减少日志的代码修改量。
总结&展望
Metrics
总结:基本实现分布式事务的可量化、可观测。 展望:更细粒度的指标、更广阔的生态兼容。
Tracing
总结:分布式事务全链路的可追溯。 展望:根据xid追溯事务链路,异常链路根因快速定位。
Logging
总结:结构化的日志格式。 展望:日志可观测体系演进。