本文主要介绍分布式事务从内部到商业化和开源的演进历程,Seata社区当前进展和未来规划。
Seata是一款开源的分布式事务解决方案,旨在为现代化微服务架构下的分布式事务提供解决方案。Seata提供了完整的分布式事务解决方案,包括AT、TCC、Saga和XA事务模式,可支持多种编程语言和数据存储方案。Seata还提供了简便易用的API,以及丰富的文档和示例,方便企业在应用Seata时进行快速开发和部署。
Seata的优势在于具有高可用性、高性能、高扩展性等特点,同时在进行横向扩展时也无需做额外的复杂操作。 目前Seata已在阿里云上几千家客户业务系统中使用,其可靠性得到了业内各大厂商的认可和应用。
作为一个开源项目,Seata的社区也在不断扩大,现已成为开发者交流、分享和学习的重要平台,也得到了越来越多企业的支持和关注。
今天我主要针对以下三个小议题对Seata进行分享:
- 从TXC/GTS 到 Seata
- Seata 社区最新进展
- Seata 社区未来规划
从TXC/GTS 到Seata
分布式事务的缘起
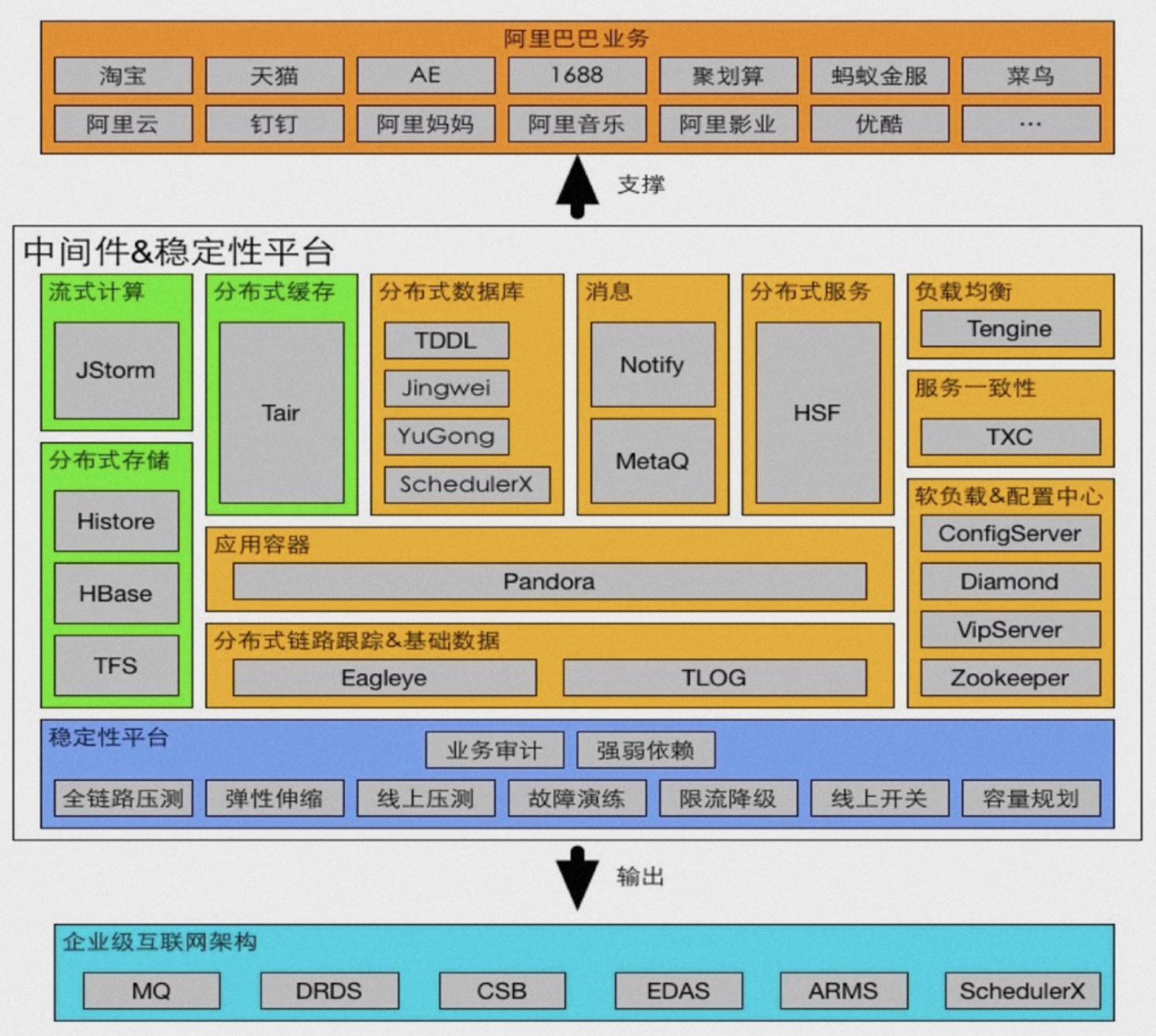 Seata 在阿里内部的产品代号叫TXC(taobao transaction constructor),这个名字有非常浓厚的组织架构色彩。TXC 起源于阿里五彩石项目,五彩石是上古神话中女娲补天所用的石子,项目名喻意为打破关键技术壁垒,象征着阿里在从单体架构向分布式架构的演进过程中的重要里程碑。在这个项目的过程中演进出一批划时代的互联网中间件,包括我们常说的三大件:
Seata 在阿里内部的产品代号叫TXC(taobao transaction constructor),这个名字有非常浓厚的组织架构色彩。TXC 起源于阿里五彩石项目,五彩石是上古神话中女娲补天所用的石子,项目名喻意为打破关键技术壁垒,象征着阿里在从单体架构向分布式架构的演进过程中的重要里程碑。在这个项目的过程中演进出一批划时代的互联网中间件,包括我们常说的三大件:
- HSF 服务调用框架
解决单体应用到服务化后的服务通信调用问题。 - TDDL 分库分表框架
解决规模化后单库存储容量和连接数问题。 - MetaQ 消息框架
解决异步调用问题。
三大件的诞生满足了微服务化业务开发的基本需求,但是微服务化后的数据一致性问题并未得到妥善解决,缺少统一的解决方案。应用微服务化后出现数据一致性问题概率远大于单体应用,从进程内调用到网络调用这种复杂的环境加剧了异常场景的产生,服务跳数的增多使得在出现业务处理异常时无法协同上下游服务同时进行数据回滚。TXC的诞生正是为了解决应用架构层数据一致性的痛点问题,TXC 核心要解决的数据一致性场景包括:
- 跨服务的一致性。 应对系统异常如调用超时和业务异常时协调上下游服务节点回滚。
- 分库分表的数据一致性。 应对业务层逻辑SQL操作的数据在不同数据分片上,保证其分库分表操作的内部事务。
- 消息发送的数据一致性。 应对数据操作和消息发送成功的不一致性问题。
为了克服以上通用场景遇到的��问题,TXC与三大件做了无缝集成。业务使用三大件开发时,完全感知不到背后TXC的存在,业务不需要考虑数据一致性的设计问题,数据一致性保证交给了框架托管,业务更加聚焦于业务本身的开发,极大的提升了开发的效率。
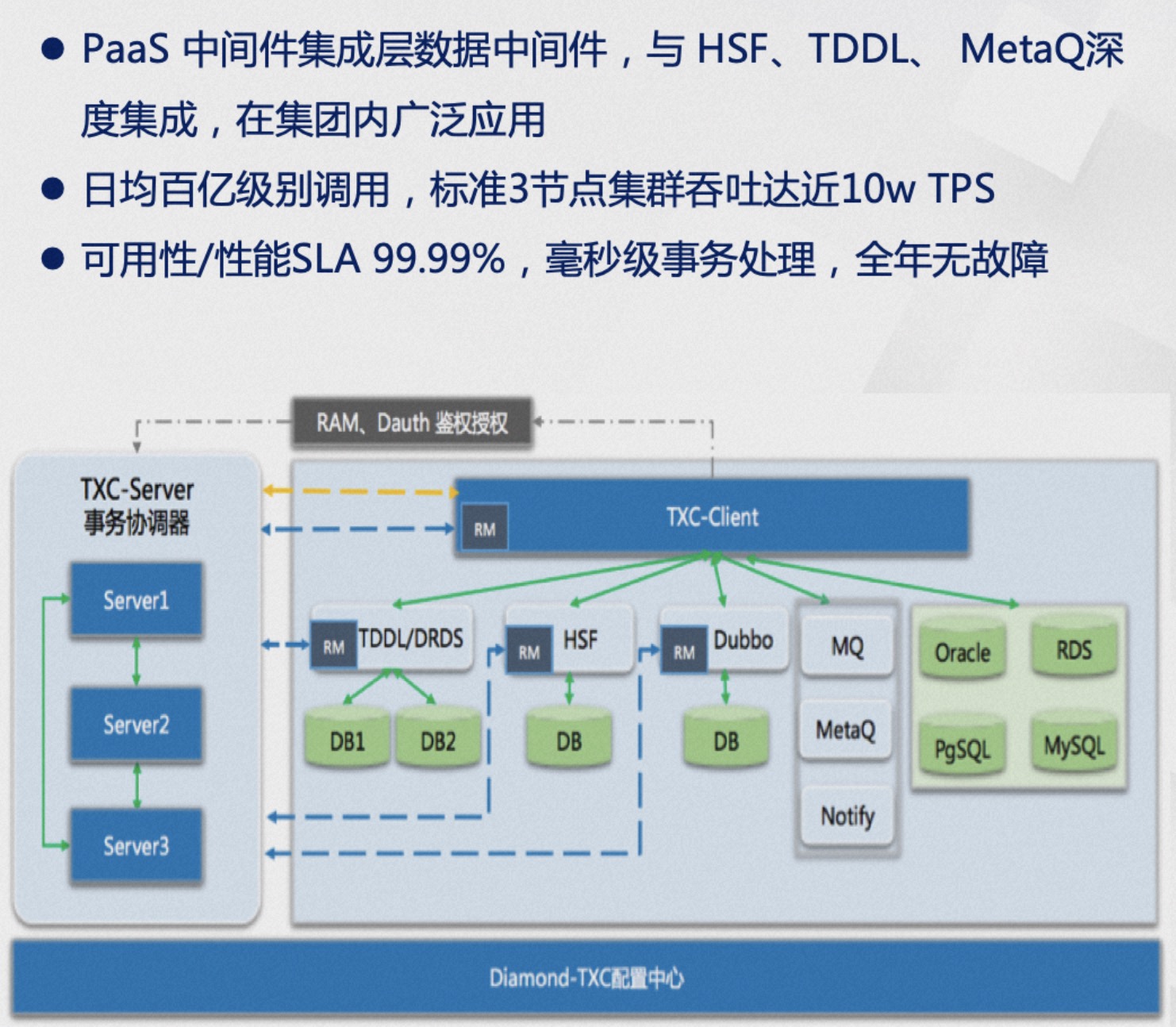
TXC已在阿里集团内部广泛应用多年,经过双11等大型活动的洪荒流量洗礼,TXC极大提高了业务的开发效率,保证了数据的正确性,消除了数据不一致导致的资损和商誉问题。随着架构的不断演进,标准的三节点集群已可以承载接近10W TPS的峰值和毫秒级事务处理。在可用性和性能方面都达到了4个9的SLA保证,即使在无值守状态下也能保证全年无故障。
分布式事务的演进
新事物的诞生总是会伴随着质疑的声音。中间件层来保证数据一致性到底可靠吗?TXC最初的诞生只是一种模糊的理论,缺乏理论模型和工程实践。在我们进行MVP(最小可行产品)模型测试并推广业务上线后,经常出现故障,常常需要在深夜起床处理问题,睡觉时要佩戴手环来应对紧急响应,这也是我接管这个团队在技术上过的最痛苦的几年。
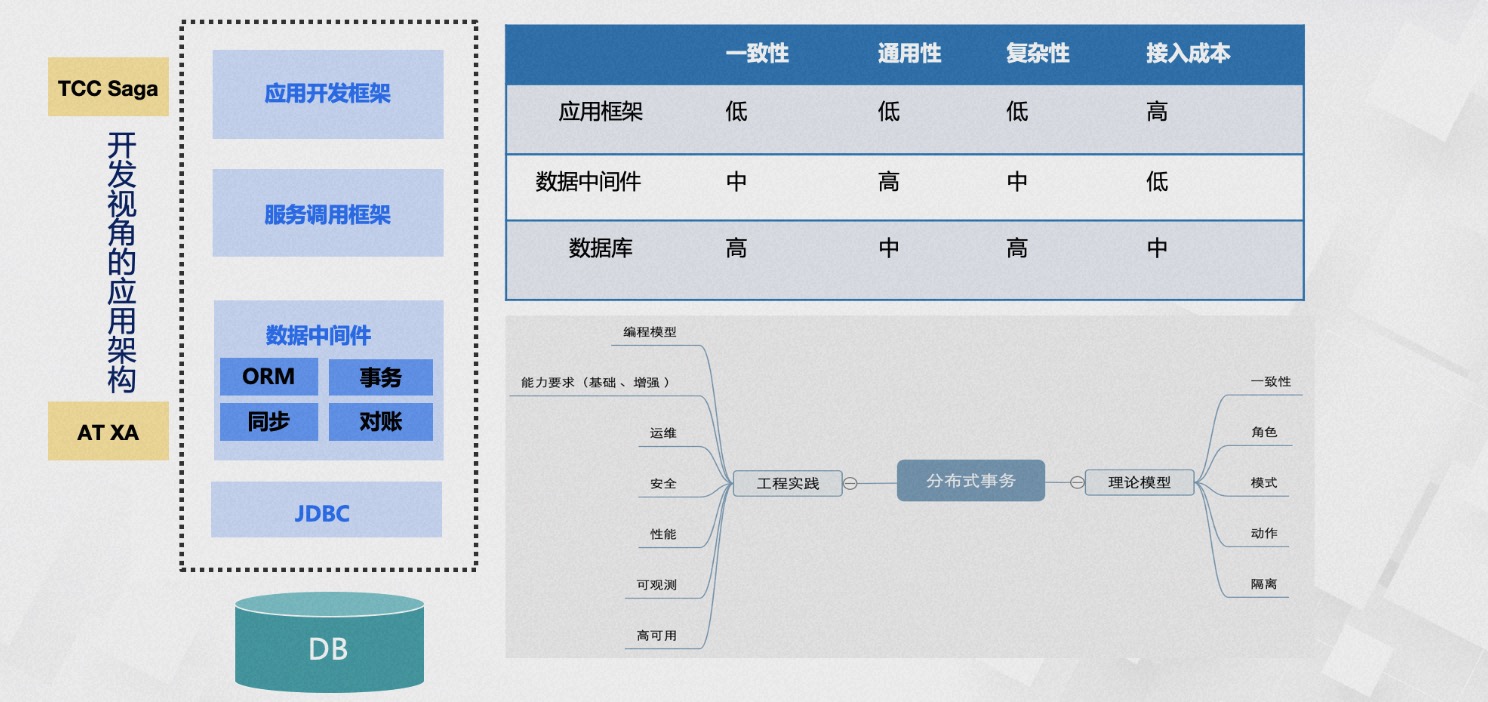
随后,我们进行了广泛的讨论和系统梳理。我们首先需要定义一致性问题,我们是要像RAFT一样实现��多数共识一致性,还是要像Google Spanner一样解决数据库一致性问题,还是其他方式?从应用节点自上而下的分层结构来看,主要包括开发框架、服务调用框架、数据中间件、数据库Driver和数据库。我们需要决定在哪一层解决数据一致性问题。我们比较了解决不同层次数据一致性问题所面临的一致性要求、通用性、实现复杂度和业务接入成本。最后,我们权衡利弊,把实现复杂度留给我们,作为一个一致性组件,我们需要确保较高的一致性,但又不能锁定到具体数据库的实现上,确保场景的通用性和业务接入成本足够低以便更容易实现业务,这也是TXC最初采用AT模式的原因。
分布式事务它不仅仅是一个框架,它是一个体系。 我们在理论上定义了一致性问题,概念上抽象出了模式、角色、动作和隔离性等。从工程实践的角度,我们定义了编程模型,包括低侵入的注解、简单的方法模板和灵活的API ,定义了事务的基础能力和增强能力(例如如何以低成本支持大量活动),以及运维、安全、性能、可观测性和高可用等方面的能力。
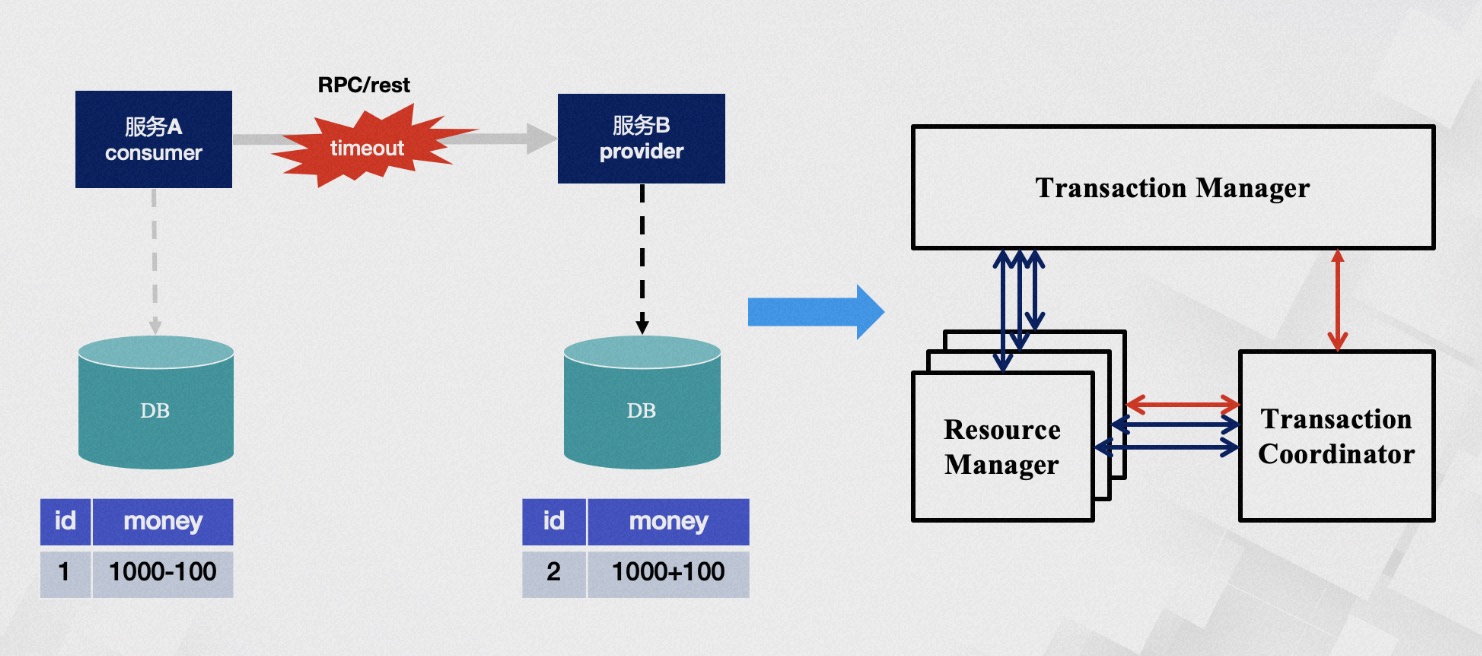 分布式事务解决了哪些问题呢?一个经典且具有体感的例子就是转账场景。转账过程包括减去余额和增加余额两个步骤,我们如何保证操作的原子性?在没有任何干预的情况下,这两个步骤可能会遇到各种问题,例如B账户已销户或出现服务调用超时等情况。
分布式事务解决了哪些问题呢?一个经典且具有体感的例子就是转账场景。转账过程包括减去余额和增加余额两个步骤,我们如何保证操作的原子性?在没有任何干预的情况下,这两个步骤可能会遇到各种问题,例如B账户已销户或出现服务调用超时等情况。
超时问题一直是分布式应用中比较难解决的问题,我们无法准确知晓B服务是否执行以及其执行顺序。从数据的角度来看,这意味着B 账户的钱未必会被成功加起来。在服�务化改造之后,每个节点仅获知部分信息,而事务本身需要全局协调所有节点,因此需要一个拥有上帝视角、能够获取全部信息的中心化角色,这个角色就是TC(transaction coordinator),它用于全局协调事务的状态。TM(Transaction Manager) 则是驱动事务生成提议的角色。但是,即使上帝也有打瞌睡的时候,他的判断也并不总是正确的,因此需要一个RM(resource manager) 角色作为灵魂的代表来验证事务的真实性。这就是TXC 最基本的哲学模型。我们从方法论上验证了它的数据一致性是非常完备的,当然,我们的认知是有边界的。也许未来会证明我们是火鸡工程师,但在当前情况下,它的模型已经足以解决大部分现有问题。
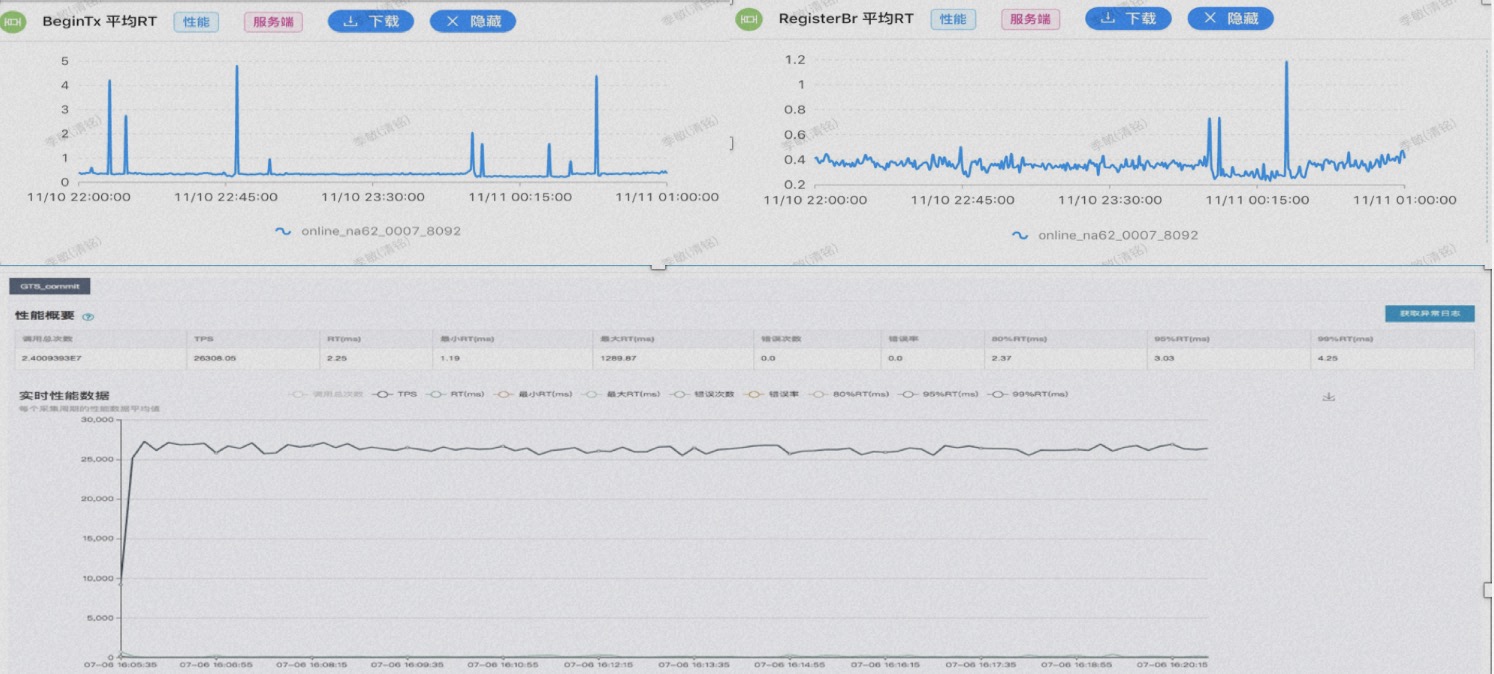 经过多年的架构演进,从事务的单链路耗时角度来看,TXC在事务开始时的处理平均时间约为0.2毫秒,分支注册的平均时间约为0.4毫秒,整个事务额外的耗时在毫秒级别之内。这也是我们推算出的极限理论值。在吞吐量方面,单节点的TPS达到3万次/秒,标准集群的TPS接近10万次/秒。
经过多年的架构演进,从事务的单链路耗时角度来看,TXC在事务开始时的处理平均时间约为0.2毫秒,分支注册的平均时间约为0.4毫秒,整个事务额外的耗时在毫秒级别之内。这也是我们推算出的极限理论值。在吞吐量方面,单节点的TPS达到3万次/秒,标准集群的TPS接近10万次/秒。
Seata 开源
为什么要做开源?这是很多人问过我的问题。2017年我们做了商业化的 GTS(Global Transaction Service )产品产品在阿里云上售卖,有公有云和专有云两种形态。此时集团内发展的顺利,但是在我们商业化的过程中并不顺利,我们遇到了各种各样的问题,问题总结起来主要包括两类:一是开发者对于分布式事务的理论相当匮乏, 大多数人连本地事务都没搞明白是怎么回事更何况是分布式事务。 二是产品成熟度上存在问题, 经常遇到稀奇古怪的场景问题,导致了支持交付成本的急剧上升,研发变成了售后客服。
我们反思为什么遇到如此多的问题,这里主要的问题是在阿里集团内部是统一语言栈和统一技术栈的,我们对特定场景的打磨是非常成熟的,服务阿里一家公司和服务云上成千上万家企业有本质的区,这也启示我们产品的场景生态做的不够好。在GitHub 80%以上的开源软件是基础软件,基础软件首要解决的是场景通用性问题,因此它不能被有一家企业Lock In,比如像Linux,它有非常多的社区分发版本。因此,为了让我们的产品变得更好,我们选择了开源,与开发者们共建,普及更多的企业用户。
 阿里的开源经历了三个主要阶段。第一个阶段是Dubbo所处的阶段,开发者用爱发电, Dubbo开源了有10几年的时间,时间充分证明了Dubbo是非常优秀的开源软件,它的微内核插件化的扩展性设计也是我最初开源Seata 的重要参考。做软件设计的时候我们要思考扩展性和性能权衡起来哪个会更重要一些,我们到底是要做一个三年的设计,五年的设计亦或是满足业务发展的十年设计。我们在做0-1服务调用问题的解决方案的同时,能否预测到1-100规模化后的治理问题。
阿里的开源经历了三个主要阶段。第一个阶段是Dubbo所处的阶段,开发者用爱发电, Dubbo开源了有10几年的时间,时间充分证明了Dubbo是非常优秀的开源软件,它的微内核插件化的扩展性设计也是我最初开源Seata 的重要参考。做软件设计的时候我们要思考扩展性和性能权衡起来哪个会更重要一些,我们到底是要做一个三年的设计,五年的设计亦或是满足业务发展的十年设计。我们在做0-1服务调用问题的解决方案的同时,能否预测到1-100规模化后的治理问题。
第二个阶段是开源和商业化的闭环,商业化反哺于开源社区,促进了开源社区的发展。 我认为云厂商更容易做好开源的原因如下:
- 首先,云是一个规模化��的经济,必然要建立在稳定成熟的内核基础上,在上面去包装其产品化能力包括高可用、免运维和弹性能力。不稳定的内核必然导致过高的交付支持成本,研发团队的支持答疑穿透过高,过高的交付成本无法实现大规模的复制,穿透率过高无法使产品快速的演进迭代。
- 其次,商业产品是更懂业务需求的。我们内部团队做技术的经常是站在研发的视角YY 需求,做出来的东西没有人使用,也就不会形成价值的转换。商业化收集到的都是真实的业务需求,因此,它的开源内核也必须会朝着这个方向演进。如果不朝着这个方向去演进必然导致两边架构上的分裂,增加团队的维护成本。
- 最后,开源和商业化闭环,能促进双方更好的发展。如果开源内核经常出现各种问题,你是否愿意相信的它的商业化产品是足够优秀的。
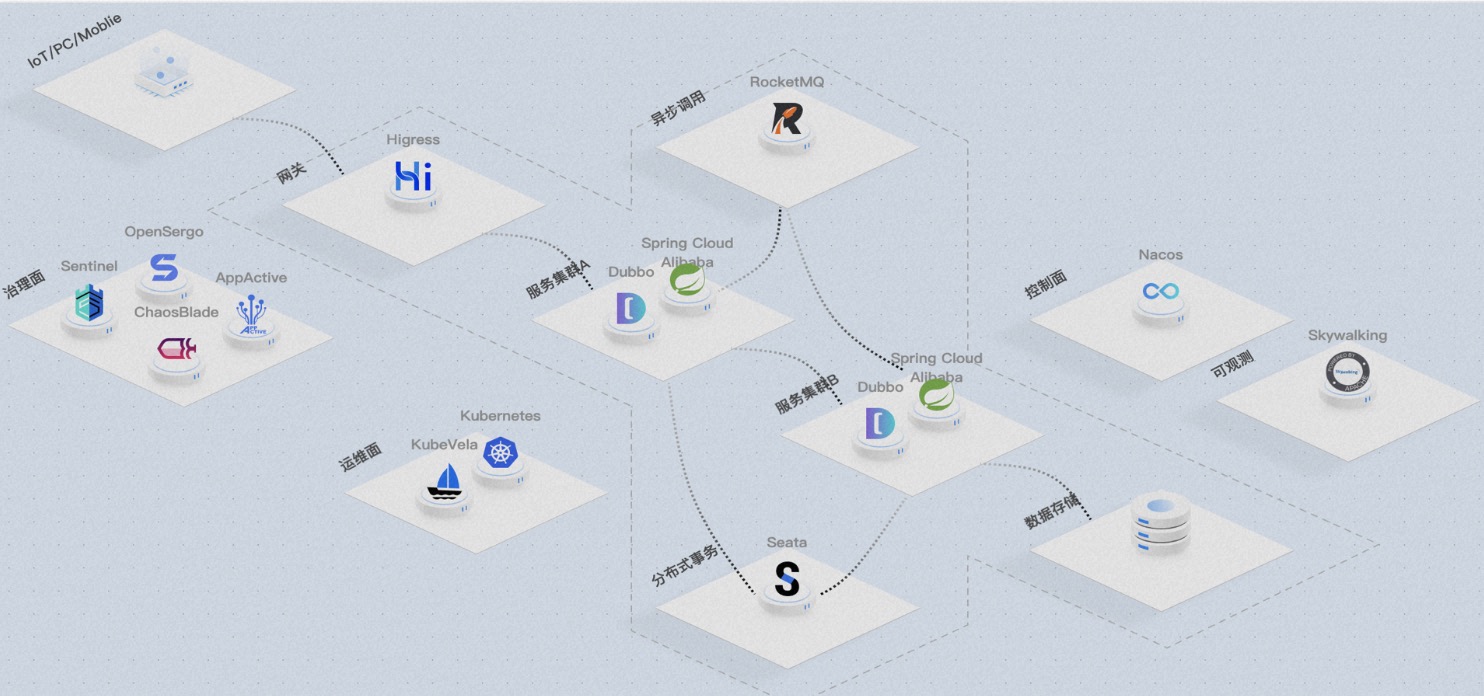
第三个阶段是体系化和标准化。 首先,体系化是开源解决方案的基础。阿里的开源项目大多是基于内部电商场景的实践而诞生的。例如Higress,它用于打通蚂蚁集团的网关;Nacos承载着服务的百万实例和千万连接;Sentinel 提供大促时的降级和限流等高可用性能力;而Seata负责保障交易数据的一致性。这套体系化的开源解决方案是基于阿里电商生态的最佳实践而设计的。其次,标准化是另一个重要的特点。以OpenSergo为例,它既是一个标准,又是一个实现。在过去几年里,国内开源项目数量呈爆发式增长。然而,各个开源产品的能力差异很大,彼此集成时会遇到许多兼容性问题。因此,像OpenSergo这样的开源项目能够定义一些标准化的能力和接口,并提供一些实现,这将为整个开源生态系统的发展提供极大的帮助。
Seata 社区最新进展
Seata 社区简介
 目前,Seata已经开源了4种事务模式,包括AT、TCC、Saga和XA,并在积极探索其他可行的事务解决方案。 Seata已经与10多个主流的RPC框架和关系数据库进行了集成,同时与20 多个社区存在集成和被集成的关系。此外,我们还在多语言体系上探索除Java之外的语言,如Golang、PHP、Python和JS。
目前,Seata已经开源了4种事务模式,包括AT、TCC、Saga和XA,并在积极探索其他可行的事务解决方案。 Seata已经与10多个主流的RPC框架和关系数据库进行了集成,同时与20 多个社区存在集成和被集成的关系。此外,我们还在多语言体系上探索除Java之外的语言,如Golang、PHP、Python和JS。
Seata已经被几千家客户应用到业务系统中。Seata的应用已经变得越来越成熟,在金融业务场景中信银行和光大银行与社区做了很好的合作,并成功将其纳入到核心账务系统中。在金融场景对微服务体系的落地是非常严苛的,这也标志着Seata的内核成熟度迈上了一个新台阶。
Seata 扩展生态
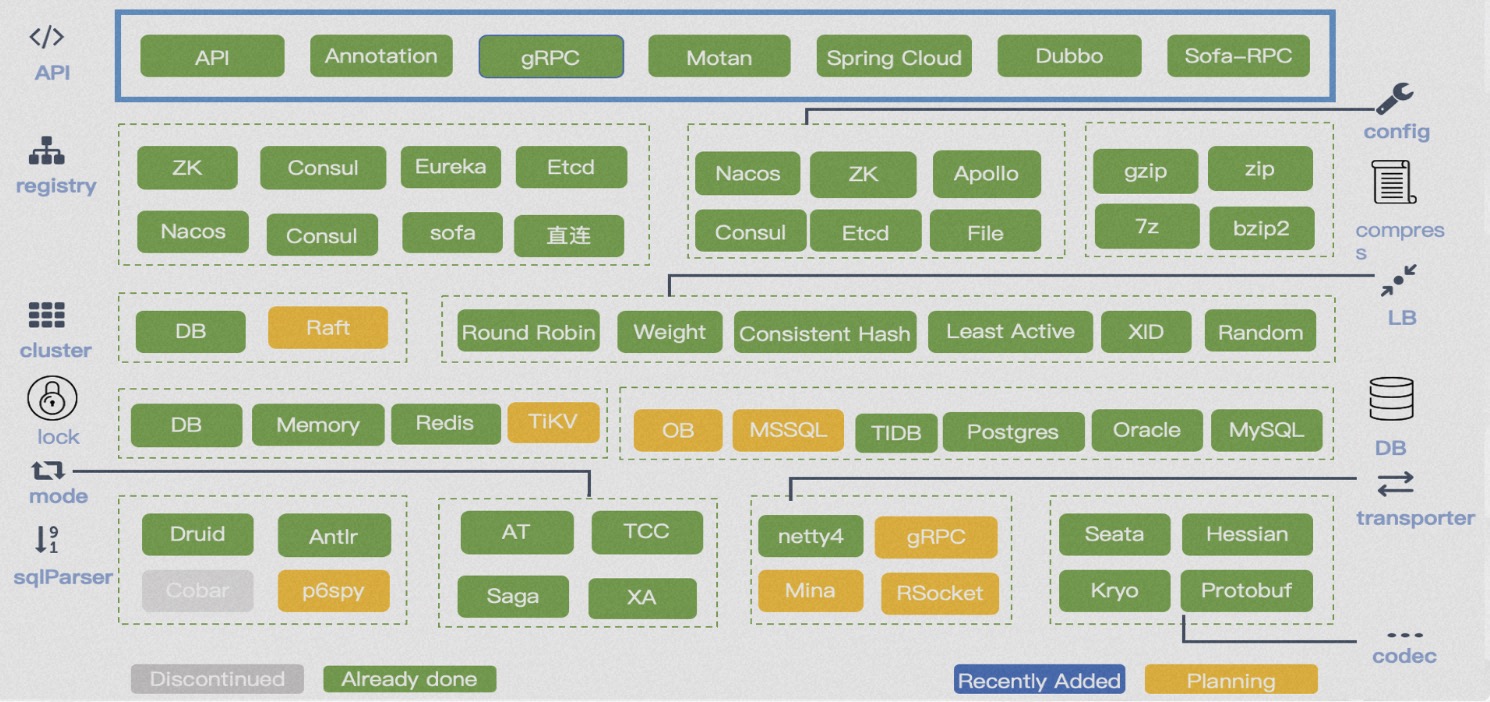 Seata采用了微内核和插件化的设计,它在API、注册配置中心、存储模式、锁控制、SQL解析器、负载均衡、传输、协议编解码、可观察性等方面暴露了丰富的扩展点。 这使得业务可以方便地进��行灵活的扩展和技术组件的选择。
Seata采用了微内核和插件化的设计,它在API、注册配置中心、存储模式、锁控制、SQL解析器、负载均衡、传输、协议编解码、可观察性等方面暴露了丰富的扩展点。 这使得业务可以方便地进��行灵活的扩展和技术组件的选择。
Seata 应用案例
 案例1:中航信航旅纵横项目
案例1:中航信航旅纵横项目
中航信航旅纵横项目在Seata 0.2版本中引入Seata解决机票和优惠券业务的数据一致性问题,大大提高了开发效率、减少了数据不一致造成的资损并提升了用户交互体验。
案例2:滴滴出行二轮车事业部
滴滴出行二轮车事业部在Seata 0.6.1版本中引入Seata,解决了小蓝单车、电动车、资产等业务流程的数据一致性问题,优化了用户使用体验并减少了资产的损失。
案例3:美团基础架构
美团基础架构团队基于开源的Seata项目开发了内部分布式事务解决方案Swan,被用于解决美团内部各业务的分布式事务问题。
场景4:盒马小镇
盒马小镇在游戏互动中使用Seata控制偷花的流程,开发周期大大缩短,从20天缩短到了5天,有效降低了开发成本。
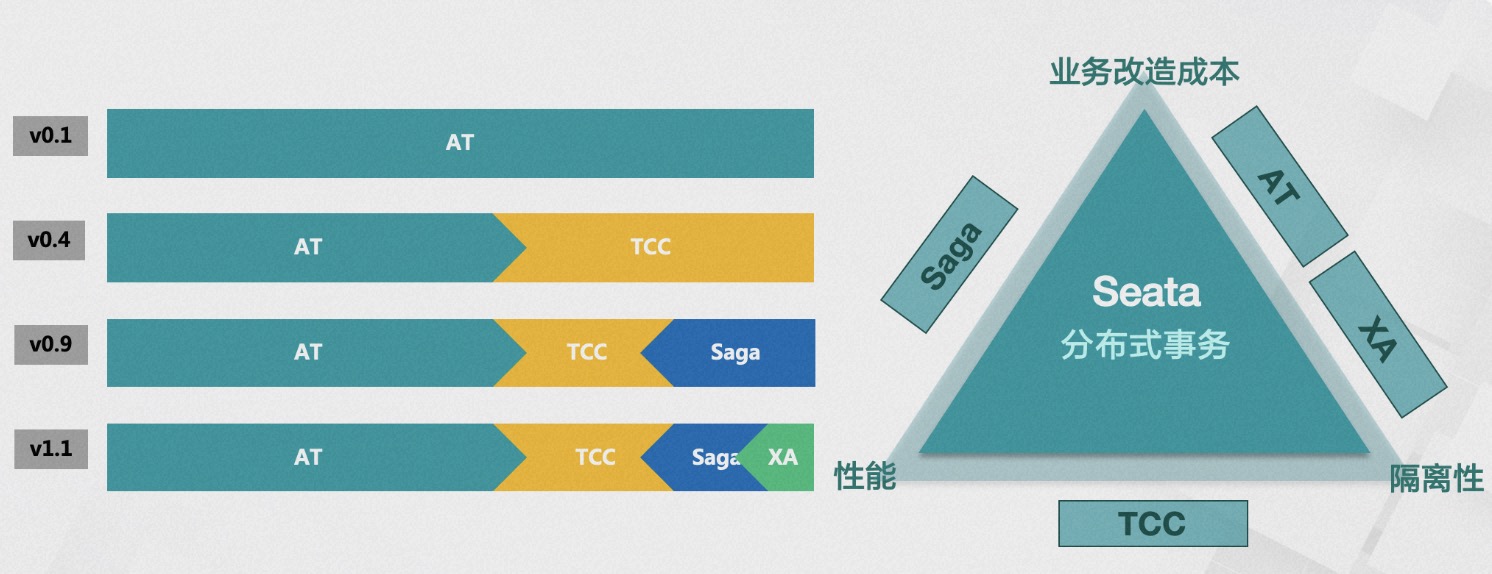
Seata 事务模式的演进
Seata 当前进展
- 支持 Oracle和 Postgresql 多主键。
- 支持 Dubbo3
- 支持 Spring Boot3
- 支持 JDK 17
- 支持 ARM64 镜像
- 支持多注册模型
- 扩展了多种SQL语法
- 支持 GraalVM Native Image
- 支持 Redis lua 存储模式
Seata 2.x 发展规划
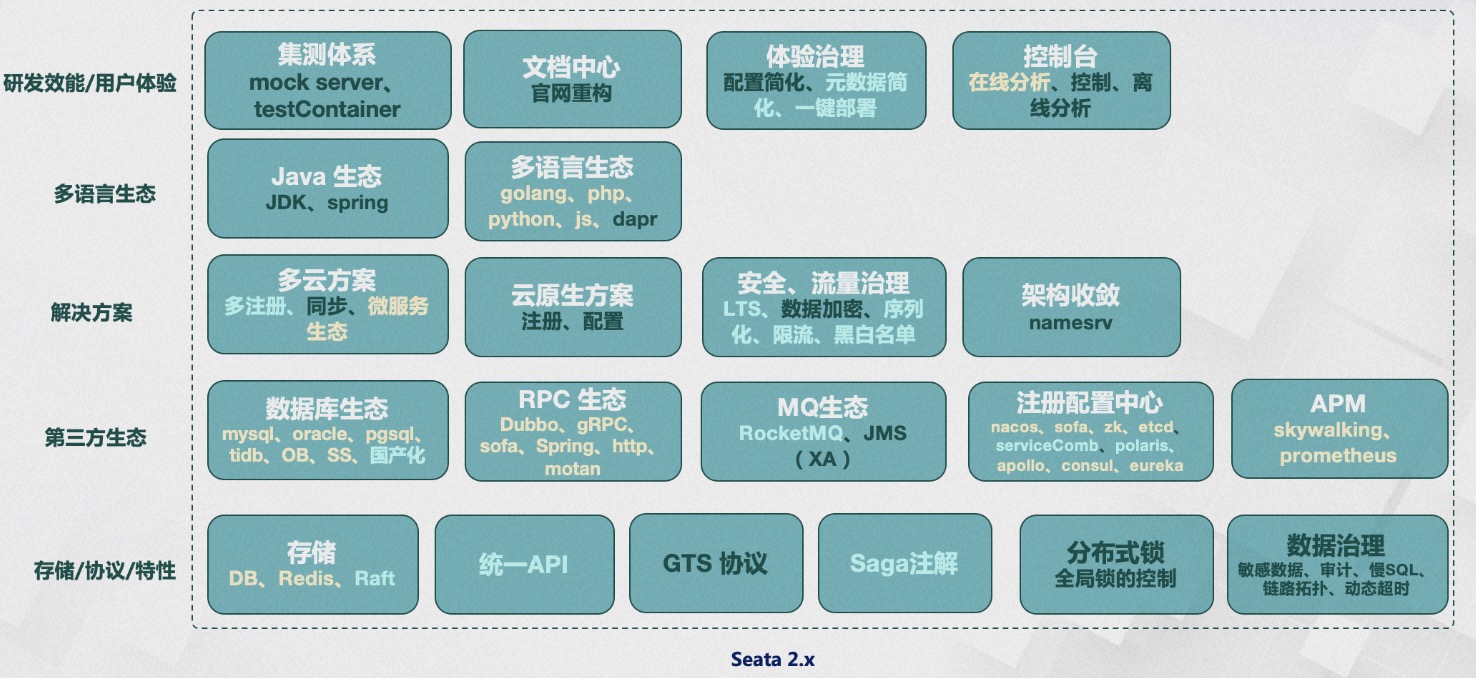
主要包括下面几个方面:
- 存储/协议/特性
存储模式上探索存算不分离的Raft集群模式;更好的体验,统一当前4种事务模式的API;兼容GTS协议;支持Saga注解;支持分布式锁的控制;支持以数据视角的洞察和治理。 - 生态
融合支持更多的数据库,更多的服务框架,同时探索国产化信创生态的支持;支持MQ生态;进一步完善APM的支持。 - 解决方案
解决方案上除了支持微服务生态探索多云方案;更贴近云原生的解决方案;增加安全和流量防护能力;实现架构上核心组件的自闭环收敛。 - 多语言生态
多语言生态中Java最成熟,其他已支持的编程语言继续完善,同时探索与语言无关的Transaction Mesh方案。 - 研发效能/体验
提升测试的覆盖率,优先保证质量、兼容性和稳定性;重构官网文档结构,提升文档搜索的命中率;在体验上简化运维部署,实现一键安装和配置元数据简化;控制台支持事务控制和在线分析能力。
一句话总结2.x 的规划:更大的场景,更大的生态,从可用到好用。
Seata 社区联系方式
