作者 | 刘晓敏 于雨
一、简介
Java 的世界里,大家广泛使用的一个高性能网络通信框架 netty,很多 RPC 框架都是基于 netty 来实现的。在 golang 的世界里,getty 也是一个类似 netty 的高性能网络通信库。getty 最初由 dubbogo 项目负责人于雨开发,作为底层通信库在 dubbo-go 中使用。随着 dubbo-go 捐献给 apache 基金会,在社区小伙伴的共同努力下,getty 也最终进入到 apache 这个大家庭,并改名 dubbo-getty 。
18 年的时候,我在公司里实践微服务,当时遇到最大的问题就是分布式事务问题。同年,阿里在社区开源他们的分布式事务解决方案,我也很快关注到这个项目,起初还叫 fescar,后来更名 seata。由于我对开源技术很感兴趣,加了很多社区群,当时也很关注 dubbo-go 这个项目,在里面默默潜水。随着对 seata 的了解,逐渐萌生了做一个 go 版本的分布式事务框架的想法。
要做一个 golang 版的分布式事务框架,首要的一个问题就是如何实现 RPC 通信。dubbo-go 就是很好的一个例子摆在眼前,遂开始研究 dubbo-go 的底层 getty。
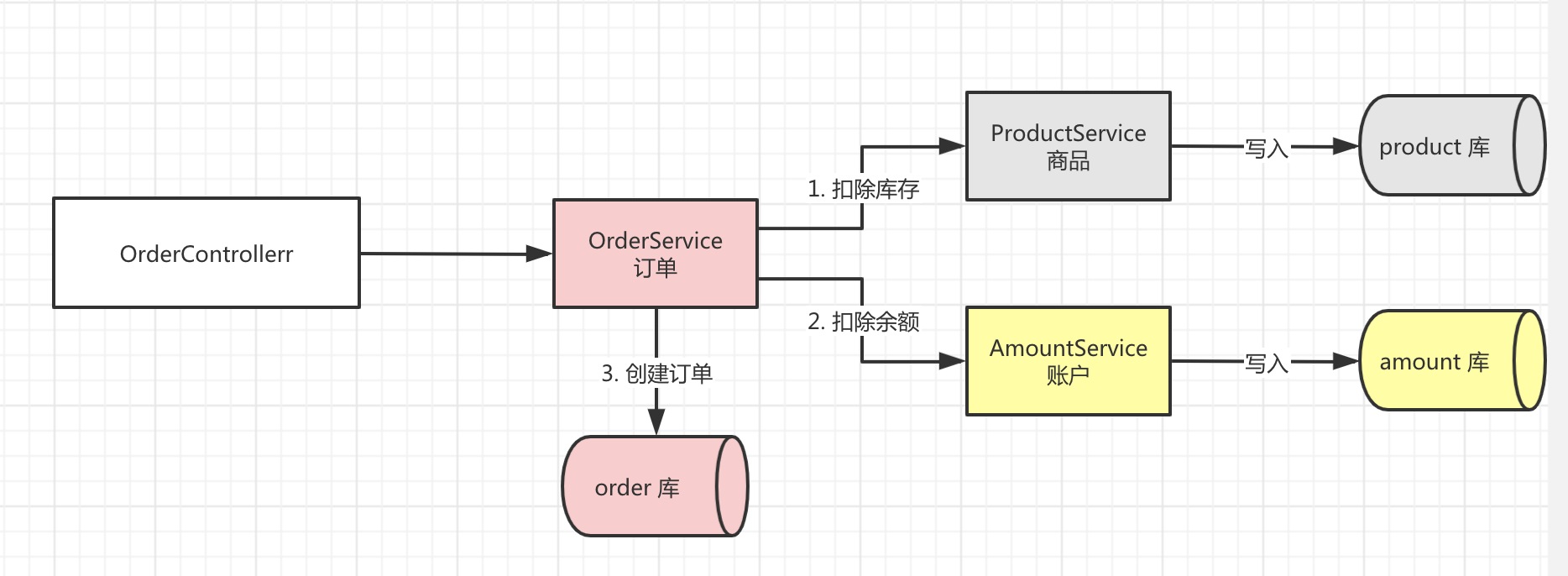
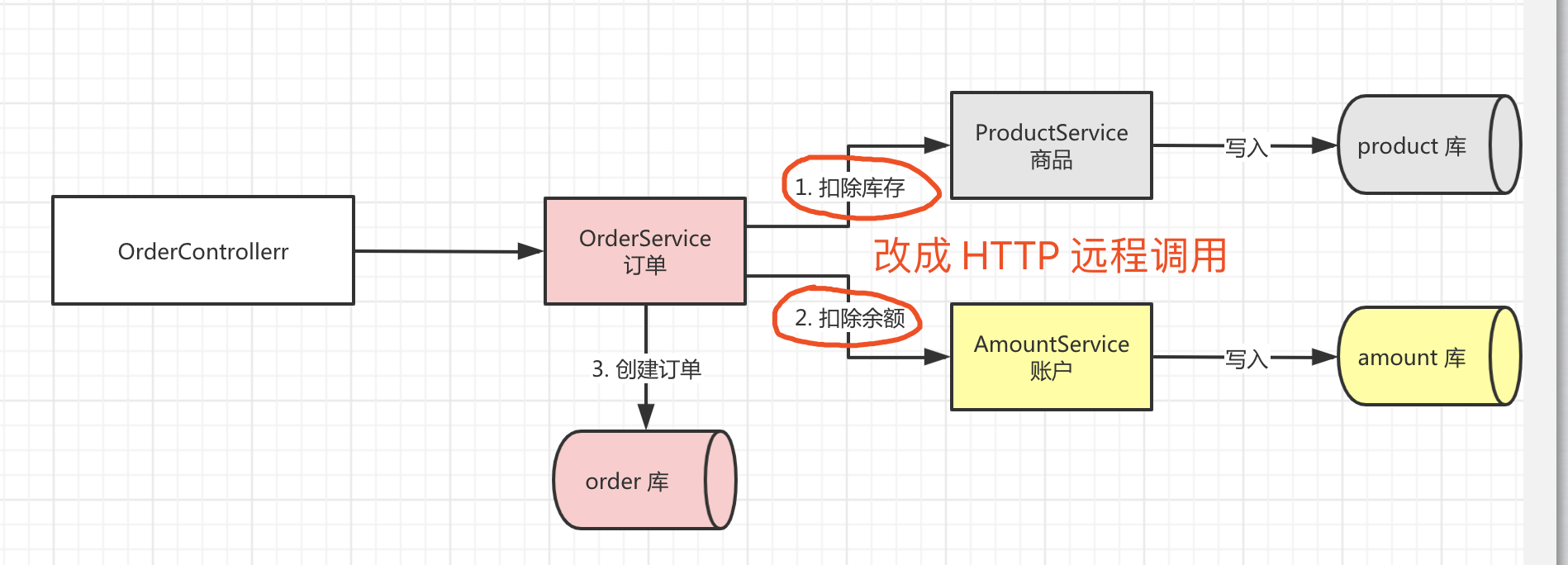
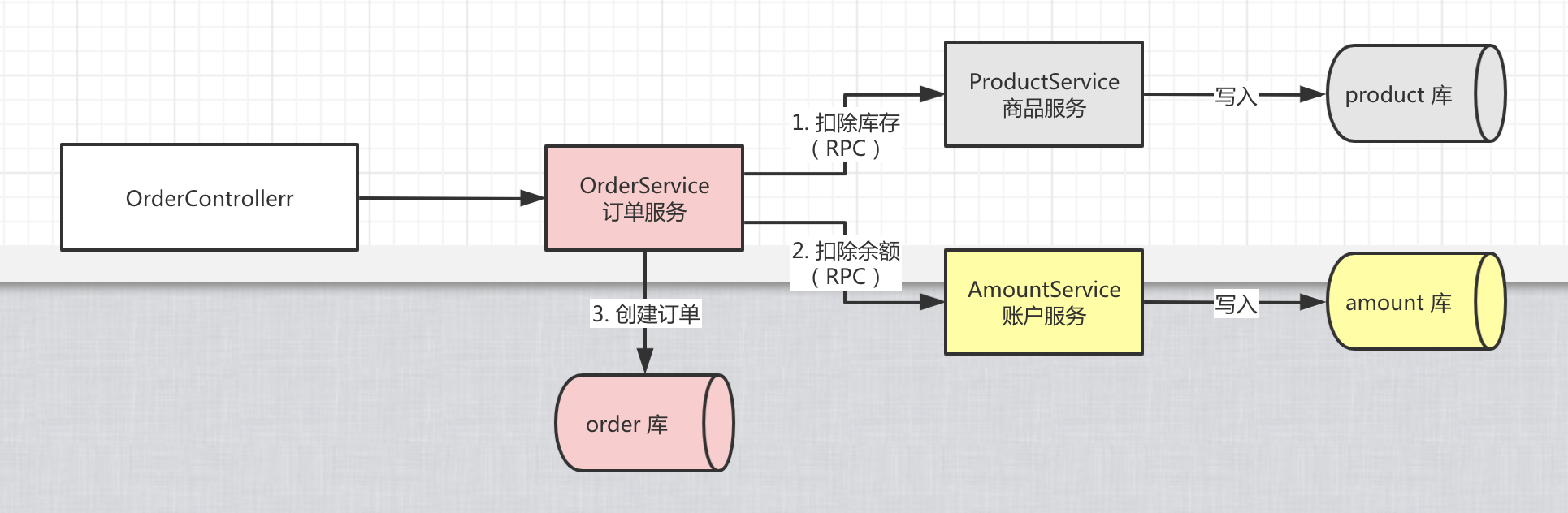
二、如何基于 getty 实现 RPC 通信
getty 框架的整体模型图如下:

下面结合相关代码,详述 seata-golang 的 RPC 通信过程。
1. 建立连接
实现 RPC 通信,首先要建立网络连接吧,我们从 client.go 开始看起。
func (c *client) connect() {
var (
err error
ss Session
)
for {
// 建立一个 session 连接
ss = c.dial()
if ss == nil {
// client has been closed
break
}
err = c.newSession(ss)
if err == nil {
// 收发报文
ss.(*session).run()
// 此处省略部分代码
break
}
// don't distinguish between tcp connection and websocket connection. Because
// gorilla/websocket/conn.go:(Conn)Close also invoke net.Conn.Close()
ss.Conn().Close()
}
}
connect() 方法通过 dial() 方法得到了一个 session 连接,进入 dial() 方法:
func (c *client) dial() Session {
switch c.endPointType {
case TCP_CLIENT:
return c.dialTCP()
case UDP_CLIENT:
return c.dialUDP()
case WS_CLIENT:
return c.dialWS()
case WSS_CLIENT:
return c.dialWSS()
}
return nil
}
我们关注的是 TCP 连接,所以继续进入 c.dialTCP() 方法:
func (c *client) dialTCP() Session {
var (
err error
conn net.Conn
)
for {
if c.IsClosed() {
return nil
}
if c.sslEnabled {
if sslConfig, err := c.tlsConfigBuilder.BuildTlsConfig(); err == nil && sslConfig != nil {
d := &net.Dialer{Timeout: connectTimeout}
// 建立加密连接
conn, err = tls.DialWithDialer(d, "tcp", c.addr, sslConfig)
}
} else {
// 建立 tcp 连接
conn, err = net.DialTimeout("tcp", c.addr, connectTimeout)
}
if err == nil && gxnet.IsSameAddr(conn.RemoteAddr(), conn.LocalAddr()) {
conn.Close()
err = errSelfConnect
}
if err == nil {
// 返回一个 TCPSession
return newTCPSession(conn, c)
}
log.Infof("net.DialTimeout(addr:%s, timeout:%v) = error:%+v", c.addr, connectTimeout, perrors.WithStack(err))
<-wheel.After(connectInterval)
}
}
至此,我们知道了 getty 如何建立 TCP 连接,并返回 TCPSession。
2. 收发报文
那它是怎么收发报文的呢,我们回到 connection 方法接着往下看,有这样一行 ss.(*session).run(),在这行代码之后代码都是很简单的操作,我们猜测这行代码运行的逻辑里面一定包含收发报文的逻辑,接着进入 run() 方法:
func (s *session) run() {
// 省略部分代码
go s.handleLoop()
go s.handlePackage()
}
这里起了两个 goroutine,handleLoop 和 handlePackage,看字面意思符合我们的猜想,进入 handleLoop() 方法:
func (s *session) handleLoop() {
// 省略部分代码
for {
// A select blocks until one of its cases is ready to run.
// It choose one at random if multiple are ready. Otherwise it choose default branch if none is ready.
select {
// 省略部分代码
case outPkg, ok = <-s.wQ:
// 省略部分代码
iovec = iovec[:0]
for idx := 0; idx < maxIovecNum; idx++ {
// 通过 s.writer 将 interface{} 类型的 outPkg 编码成二进制的比特
pkgBytes, err = s.writer.Write(s, outPkg)
// 省略部分代码
iovec = append(iovec, pkgBytes)
//省略部分代码
}
// 将这些二进制比特发送出去
err = s.WriteBytesArray(iovec[:]...)
if err != nil {
log.Errorf("%s, [session.handleLoop]s.WriteBytesArray(iovec len:%d) = error:%+v",
s.sessionToken(), len(iovec), perrors.WithStack(err))
s.stop()
// break LOOP
flag = false
}
case <-wheel.After(s.period):
if flag {
if wsFlag {
err := wsConn.writePing()
if err != nil {
log.Warnf("wsConn.writePing() = error:%+v", perrors.WithStack(err))
}
}
// 定时执行的逻辑,心跳等
s.listener.OnCron(s)
}
}
}
}
通过上面的代码,我们不难发现,handleLoop() 方法处理的是发送报文的逻辑,RPC 需要发送的消息首先由 s.writer 编码成二进制比特,然后通过建立的 TCP 连接发送出去。这个 s.writer 对应的 Writer 接口是 RPC 框架必须要实现的一个接口。
继续看 handlePackage() 方法:
func (s *session) handlePackage() {
// 省略部分代码
if _, ok := s.Connection.(*gettyTCPConn); ok {
if s.reader == nil {
errStr := fmt.Sprintf("session{name:%s, conn:%#v, reader:%#v}", s.name, s.Connection, s.reader)
log.Error(errStr)
panic(errStr)
}
err = s.handleTCPPackage()
} else if _, ok := s.Connection.(*gettyWSConn); ok {
err = s.handleWSPackage()
} else if _, ok := s.Connection.(*gettyUDPConn); ok {
err = s.handleUDPPackage()
} else {
panic(fmt.Sprintf("unknown type session{%#v}", s))
}
}
进入 handleTCPPackage() 方法:
func (s *session) handleTCPPackage() error {
// 省略部分代码
conn = s.Connection.(*gettyTCPConn)
for {
// 省略部分代码
bufLen = 0
for {
// for clause for the network timeout condition check
// s.conn.SetReadTimeout(time.Now().Add(s.rTimeout))
// 从 TCP 连接中收到报文
bufLen, err = conn.recv(buf)
// 省略部分代码
break
}
// 省略部分代码
// 将收到的报文二进制比特写入 pkgBuf
pktBuf.Write(buf[:bufLen])
for {
if pktBuf.Len() <= 0 {
break
}
// 通过 s.reader 将收到的报文解码成 RPC 消息
pkg, pkgLen, err = s.reader.Read(s, pktBuf.Bytes())
// 省略部分代码
s.UpdateActive()
// 将收到的消息放入 TaskQueue 供 RPC 消费端消费
s.addTask(pkg)
pktBuf.Next(pkgLen)
// continue to handle case 5
}
if exit {
break
}
}
return perrors.WithStack(err)
}
从上面的代码逻辑我们分析出,RPC 消费端需要将从 TCP 连接收到的二进制比特报文解码成 RPC 能消费的消息,这个工作由 s.reader 实现,所以,我们要构建 RPC 通信层也需要实现 s.reader 对应的 Reader 接口。
3. 底层处理网络报文的逻辑如何与业务逻辑解耦
我们都知道,netty 通过 boss 线程和 worker 线程实现了底层网络逻辑和业务逻辑的解耦。那么,getty 是如何实现的呢?
在 handlePackage() 方法最后,我们看到,收到的消息被放入了 s.addTask(pkg) 这个方法,接着往下分析:
func (s *session) addTask(pkg interface{}) {
f := func() {
s.listener.OnMessage(s, pkg)
s.incReadPkgNum()
}
if taskPool := s.EndPoint().GetTaskPool(); taskPool != nil {
taskPool.AddTaskAlways(f)
return
}
f()
}
pkg 参数传递到了一个匿名方法,这个方法最终放入了 taskPool。这个方法很关键,在我后来写 seata-golang 代码的时候,就遇到了一个坑,这个坑后面分析。
接着我们看一下 taskPool 的定义:
// NewTaskPoolSimple build a simple task pool
func NewTaskPoolSimple(size int) GenericTaskPool {
if size < 1 {
size = runtime.NumCPU() * 100
}
return &taskPoolSimple{
work: make(chan task),
sem: make(chan struct{}, size),
done: make(chan struct{}),
}
}
构建了一个缓冲大小为 size (默认为 runtime.NumCPU() * 100) 的 channel sem。再看方法 AddTaskAlways(t task):
func (p *taskPoolSimple) AddTaskAlways(t task) {
select {
case <-p.done:
return
default:
}
select {
case p.work <- t:
return
default:
}
select {
case p.work <- t:
case p.sem <- struct{}{}:
p.wg.Add(1)
go p.worker(t)
default:
goSafely(t)
}
}
加入的任务,会先由 len(p.sem) 个 goroutine 去消费,如果没有 goroutine 空闲,则会启动一个临时的 goroutine 去运行 t()。相当于有 len(p.sem) 个 goroutine 组成了 goroutine pool,pool 中的 goroutine 去处理业务逻辑,而不是由处理网络报文的 goroutine 去运行业务逻辑,从而实现了解耦。写 seata-golang 时遇到的一个坑,就是忘记设置 taskPool 造成了处理业务逻辑和处理底层网络报文逻辑的 goroutine 是同一个,我在业务逻辑中阻塞等待一个任务完成时,阻塞了整个 goroutine,使得阻塞期间收不到任何报文。
4. 具体实现
下面的代码见 getty.go:
// Reader is used to unmarshal a complete pkg from buffer
type Reader interface {
Read(Session, []byte) (interface{}, int, error)
}
// Writer is used to marshal pkg and write to session
type Writer interface {
// if @Session is udpGettySession, the second parameter is UDPContext.
Write(Session, interface{}) ([]byte, error)
}
// ReadWriter interface use for handle application packages
type ReadWriter interface {
Reader
Writer
}
// EventListener is used to process pkg that received from remote session
type EventListener interface {
// invoked when session opened
// If the return error is not nil, @Session will be closed.
OnOpen(Session) error
// invoked when session closed.
OnClose(Session)
// invoked when got error.
OnError(Session, error)
// invoked periodically, its period can be set by (Session)SetCronPeriod
OnCron(Session)
// invoked when getty received a package. Pls attention that do not handle long time
// logic processing in this func. You'd better set the package's maximum length.
// If the message's length is greater than it, u should should return err in
// Reader{Read} and getty will close this connection soon.
//
// If ur logic processing in this func will take a long time, u should start a goroutine
// pool(like working thread pool in cpp) to handle the processing asynchronously. Or u
// can do the logic processing in other asynchronous way.
// !!!In short, ur OnMessage callback func should return asap.
//
// If this is a udp event listener, the second parameter type is UDPContext.
OnMessage(Session, interface{})
}
通过对整个 getty 代码的分析,我们只要实现 ReadWriter 来对 RPC 消息编解码,再实现 EventListener 来处理 RPC 消息的对应的具体逻辑,将 ReadWriter 实现和 EventLister 实现注入到 RPC 的 Client 和 Server 端,则可实现 RPC 通信。
4.1 编解码协议实现
下面是 seata 协议的定义:
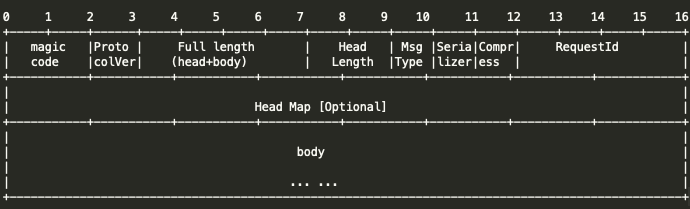
在 ReadWriter 接口的实现 RpcPackageHandler 中,调用 Codec 方法对消息体按照上面的格式编解码:
// 消息编码为二进制比特
func MessageEncoder(codecType byte, in interface{}) []byte {
switch codecType {
case SEATA:
return SeataEncoder(in)
default:
log.Errorf("not support codecType, %s", codecType)
return nil
}
}
// 二进制比特解码为消息体
func MessageDecoder(codecType byte, in []byte) (interface{}, int) {
switch codecType {
case SEATA:
return SeataDecoder(in)
default:
log.Errorf("not support codecType, %s", codecType)
return nil, 0
}
}
4.2 Client 端实现
再来看 client 端 EventListener 的实现 RpcRemotingClient:
func (client *RpcRemoteClient) OnOpen(session getty.Session) error {
go func()
request := protocal.RegisterTMRequest{AbstractIdentifyRequest: protocal.AbstractIdentifyRequest{
ApplicationId: client.conf.ApplicationId,
TransactionServiceGroup: client.conf.TransactionServiceGroup,
}}
// 建立连接后向 Transaction Coordinator 发起注册 TransactionManager 的请求
_, err := client.sendAsyncRequestWithResponse(session, request, RPC_REQUEST_TIMEOUT)
if err == nil {
// 将与 Transaction Coordinator 建立的连接保存在连接池供后续使用
clientSessionManager.RegisterGettySession(session)
client.GettySessionOnOpenChannel <- session.RemoteAddr()
}
}()
return nil
}
// OnError ...
func (client *RpcRemoteClient) OnError(session getty.Session, err error) {
clientSessionManager.ReleaseGettySession(session)
}
// OnClose ...
func (client *RpcRemoteClient) OnClose(session getty.Session) {
clientSessionManager.ReleaseGettySession(session)
}
// OnMessage ...
func (client *RpcRemoteClient) OnMessage(session getty.Session, pkg interface{}) {
log.Info("received message:{%v}", pkg)
rpcMessage, ok := pkg.(protocal.RpcMessage)
if ok {
heartBeat, isHeartBeat := rpcMessage.Body.(protocal.HeartBeatMessage)
if isHeartBeat && heartBeat == protocal.HeartBeatMessagePong {
log.Debugf("received PONG from %s", session.RemoteAddr())
}
}
if rpcMessage.MessageType == protocal.MSGTYPE_RESQUEST ||
rpcMessage.MessageType == protocal.MSGTYPE_RESQUEST_ONEWAY {
log.Debugf("msgId:%s, body:%v", rpcMessage.Id, rpcMessage.Body)
// 处理事务消息,提交 or 回滚
client.onMessage(rpcMessage, session.RemoteAddr())
} else {
resp, loaded := client.futures.Load(rpcMessage.Id)
if loaded {
response := resp.(*getty2.MessageFuture)
response.Response = rpcMessage.Body
response.Done <- true
client.futures.Delete(rpcMessage.Id)
}
}
}
// OnCron ...
func (client *RpcRemoteClient) OnCron(session getty.Session) {
// 发送心跳
client.defaultSendRequest(session, protocal.HeartBeatMessagePing)
}
clientSessionManager.RegisterGettySession(session) 的逻辑 4.4 小节分析。
4.3 Server 端 Transaction Coordinator 实现
代码见 DefaultCoordinator:
func (coordinator *DefaultCoordinator) OnOpen(session getty.Session) error {
log.Infof("got getty_session:%s", session.Stat())
return nil
}
func (coordinator *DefaultCoordinator) OnError(session getty.Session, err error) {
// 释放 TCP 连接
SessionManager.ReleaseGettySession(session)
session.Close()
log.Errorf("getty_session{%s} got error{%v}, will be closed.", session.Stat(), err)
}
func (coordinator *DefaultCoordinator) OnClose(session getty.Session) {
log.Info("getty_session{%s} is closing......", session.Stat())
}
func (coordinator *DefaultCoordinator) OnMessage(session getty.Session, pkg interface{}) {
log.Debugf("received message:{%v}", pkg)
rpcMessage, ok := pkg.(protocal.RpcMessage)
if ok {
_, isRegTM := rpcMessage.Body.(protocal.RegisterTMRequest)
if isRegTM {
// 将 TransactionManager 信息和 TCP 连接建立映射关系
coordinator.OnRegTmMessage(rpcMessage, session)
return
}
heartBeat, isHeartBeat := rpcMessage.Body.(protocal.HeartBeatMessage)
if isHeartBeat && heartBeat == protocal.HeartBeatMessagePing {
coordinator.OnCheckMessage(rpcMessage, session)
return
}
if rpcMessage.MessageType == protocal.MSGTYPE_RESQUEST ||
rpcMessage.MessageType == protocal.MSGTYPE_RESQUEST_ONEWAY {
log.Debugf("msgId:%s, body:%v", rpcMessage.Id, rpcMessage.Body)
_, isRegRM := rpcMessage.Body.(protocal.RegisterRMRequest)
if isRegRM {
// 将 ResourceManager 信息和 TCP 连接建立映射关系
coordinator.OnRegRmMessage(rpcMessage, session)
} else {
if SessionManager.IsRegistered(session) {
defer func() {
if err := recover(); err != nil {
log.Errorf("Catch Exception while do RPC, request: %v,err: %w", rpcMessage, err)
}
}()
// 处理事务消息,全局事务注册、分支事务注册、分支事务提交、全局事务回滚等
coordinator.OnTrxMessage(rpcMessage, session)
} else {
session.Close()
log.Infof("close a unhandled connection! [%v]", session)
}
}
} else {
resp, loaded := coordinator.futures.Load(rpcMessage.Id)
if loaded {
response := resp.(*getty2.MessageFuture)
response.Response = rpcMessage.Body
response.Done <- true
coordinator.futures.Delete(rpcMessage.Id)
}
}
}
}
func (coordinator *DefaultCoordinator) OnCron(session getty.Session) {
}
coordinator.OnRegTmMessage(rpcMessage, session) 注册 Transaction Manager,coordinator.OnRegRmMessage(rpcMessage, session) 注册 Resource Manager。具体逻辑分析见 4.4 小节。
消息进入 coordinator.OnTrxMessage(rpcMessage, session) 方法,将按照消息的类型码路由到具体的逻辑当中:
switch msg.GetTypeCode() {
case protocal.TypeGlobalBegin:
req := msg.(protocal.GlobalBeginRequest)
resp := coordinator.doGlobalBegin(req, ctx)
return resp
case protocal.TypeGlobalStatus:
req := msg.(protocal.GlobalStatusRequest)
resp := coordinator.doGlobalStatus(req, ctx)
return resp
case protocal.TypeGlobalReport:
req := msg.(protocal.GlobalReportRequest)
resp := coordinator.doGlobalReport(req, ctx)
return resp
case protocal.TypeGlobalCommit:
req := msg.(protocal.GlobalCommitRequest)
resp := coordinator.doGlobalCommit(req, ctx)
return resp
case protocal.TypeGlobalRollback:
req := msg.(protocal.GlobalRollbackRequest)
resp := coordinator.doGlobalRollback(req, ctx)
return resp
case protocal.TypeBranchRegister:
req := msg.(protocal.BranchRegisterRequest)
resp := coordinator.doBranchRegister(req, ctx)
return resp
case protocal.TypeBranchStatusReport:
req := msg.(protocal.BranchReportRequest)
resp := coordinator.doBranchReport(req, ctx)
return resp
default:
return nil
}
4.4 session manager 分析
Client 端同 Transaction Coordinator 建立连接起连接后,通过 clientSessionManager.RegisterGettySession(session) 将连接保存在 serverSessions = sync.Map{} 这个 map 中。map 的 key 为从 session 中获取的 RemoteAddress 即 Transaction Coordinator 的地址,value 为 session。这样,Client 端就可以通过 map 中的一个 session 来向 Transaction Coordinator 注册 Transaction Manager 和 Resource Manager 了。具体代码见 getty_client_session_manager.go。
Transaction Manager 和 Resource Manager 注册到 Transaction Coordinator 后,一个连接既有可能用来发送 TM 消息也有可能用来发送 RM 消息。我们通过 RpcContext 来标识一个连接信息:
type RpcContext struct {
Version string
TransactionServiceGroup string
ClientRole meta.TransactionRole
ApplicationId string
ClientId string
ResourceSets *model.Set
Session getty.Session
}
当收到事务消息时,我们需要构造这样一个 RpcContext 供后续事务处理逻辑使用。所以,我们会构造下列 map 来缓存映射关系:
var (
// session -> transactionRole
// TM will register before RM, if a session is not the TM registered,
// it will be the RM registered
session_transactionroles = sync.Map{}
// session -> applicationId
identified_sessions = sync.Map{}
// applicationId -> ip -> port -> session
client_sessions = sync.Map{}
// applicationId -> resourceIds
client_resources = sync.Map{}
)
这样,Transaction Manager 和 Resource Manager 分别通过 coordinator.OnRegTmMessage(rpcMessage, session) 和 coordinator.OnRegRmMessage(rpcMessage, session) 注册到 Transaction Coordinator 时,会在上述 client_sessions map 中缓存 applicationId、ip、port 与 session 的关系,在 client_resources map 中缓存 applicationId 与 resourceIds(一个应用可能存在多个 Resource Manager) 的关系。在需要时,我们就可以通过上述映射关系构造一个 RpcContext。这部分的实现和 java 版 seata 有很大的不同,感兴趣的可以深入了解一下。具体代码见 getty_session_manager.go。
至此,我们就分析完了 seata-golang 整个 RPC 通信模型的机制。
三、seata-golang 的未来
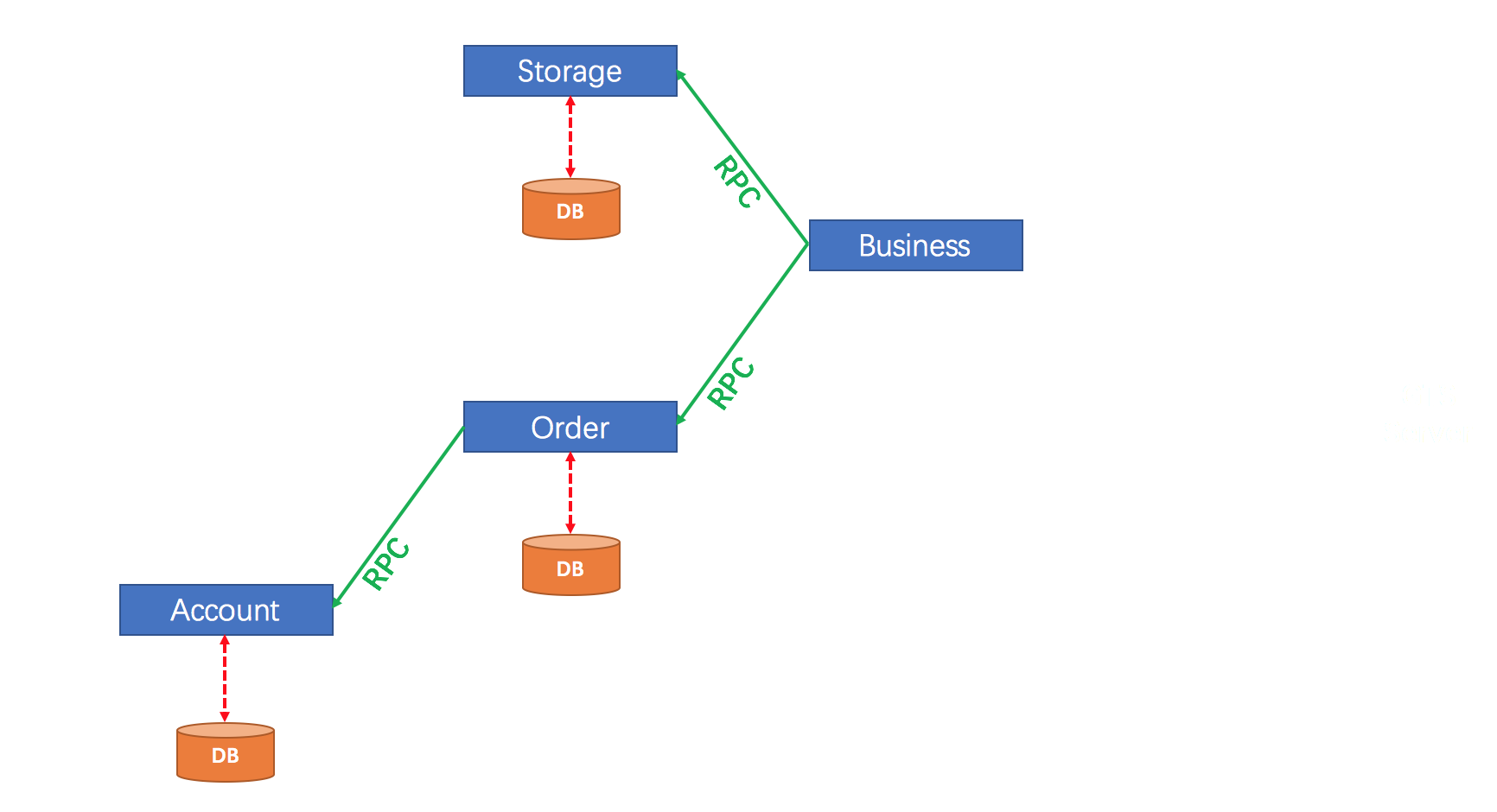
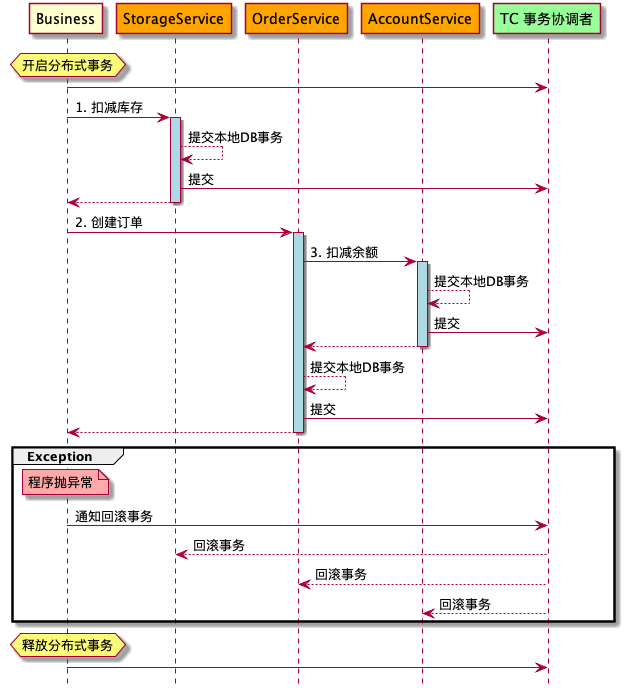
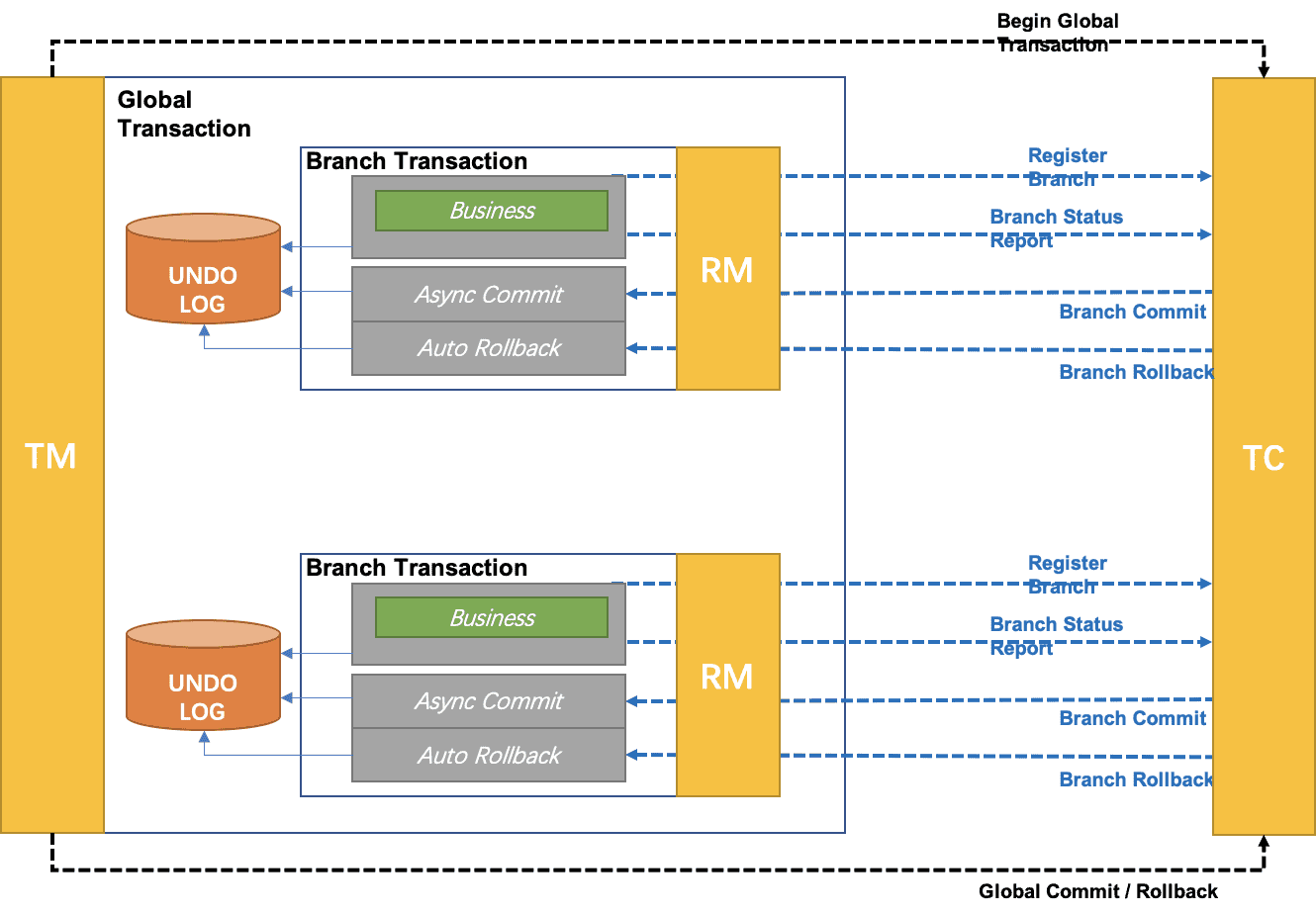
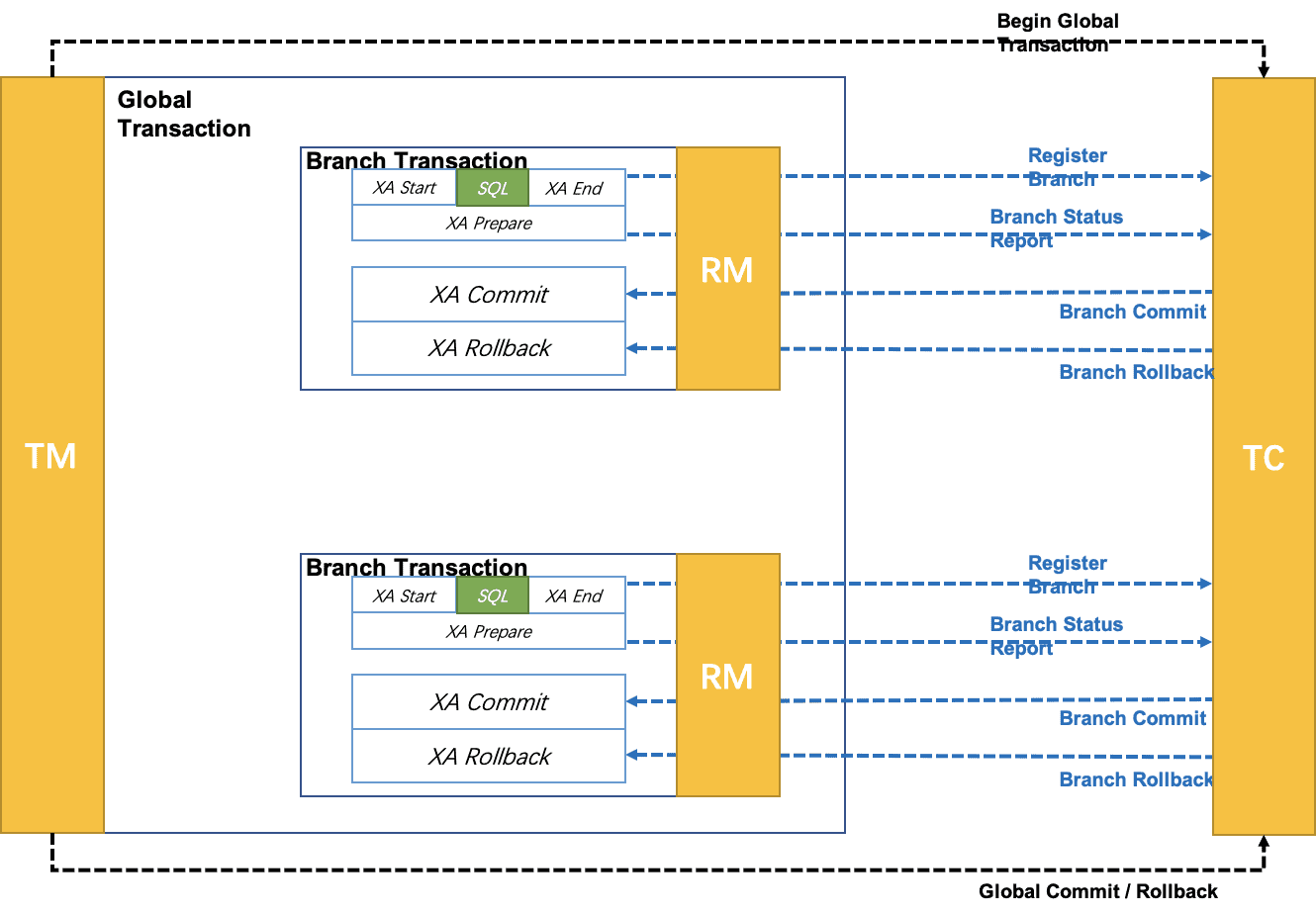
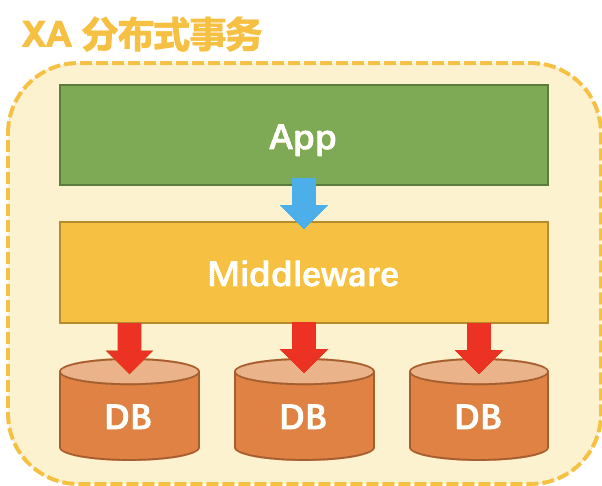
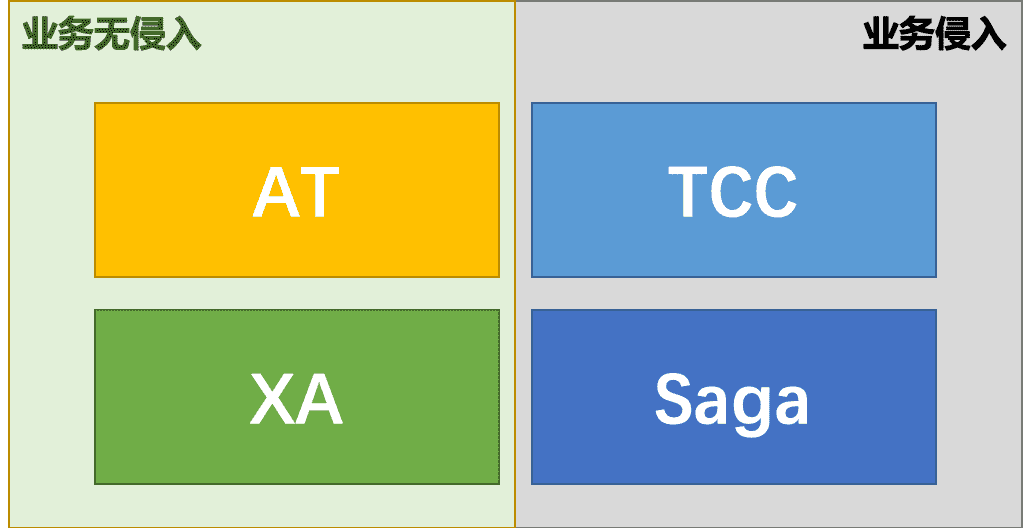
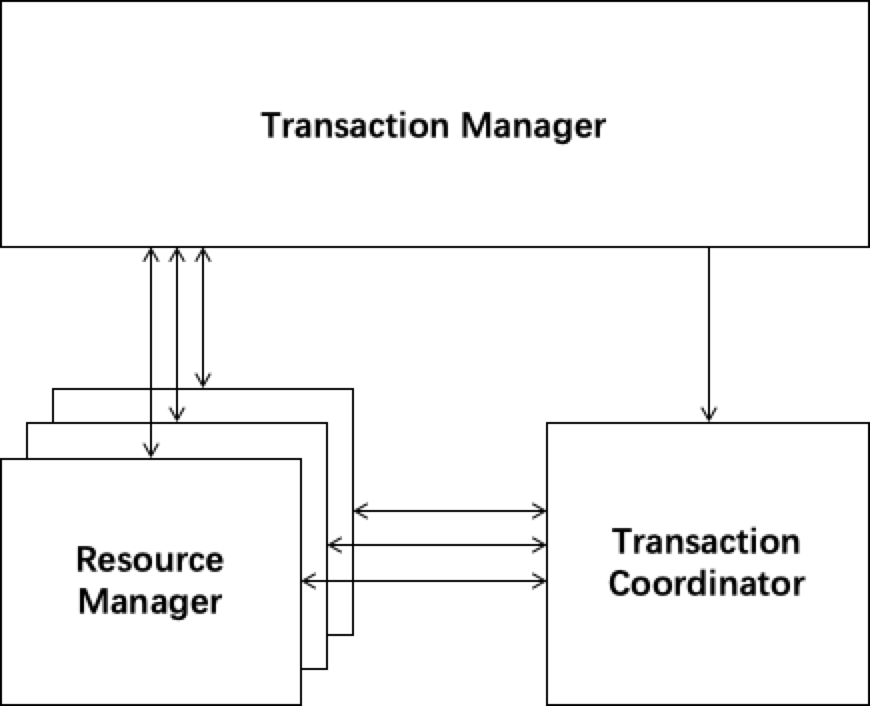
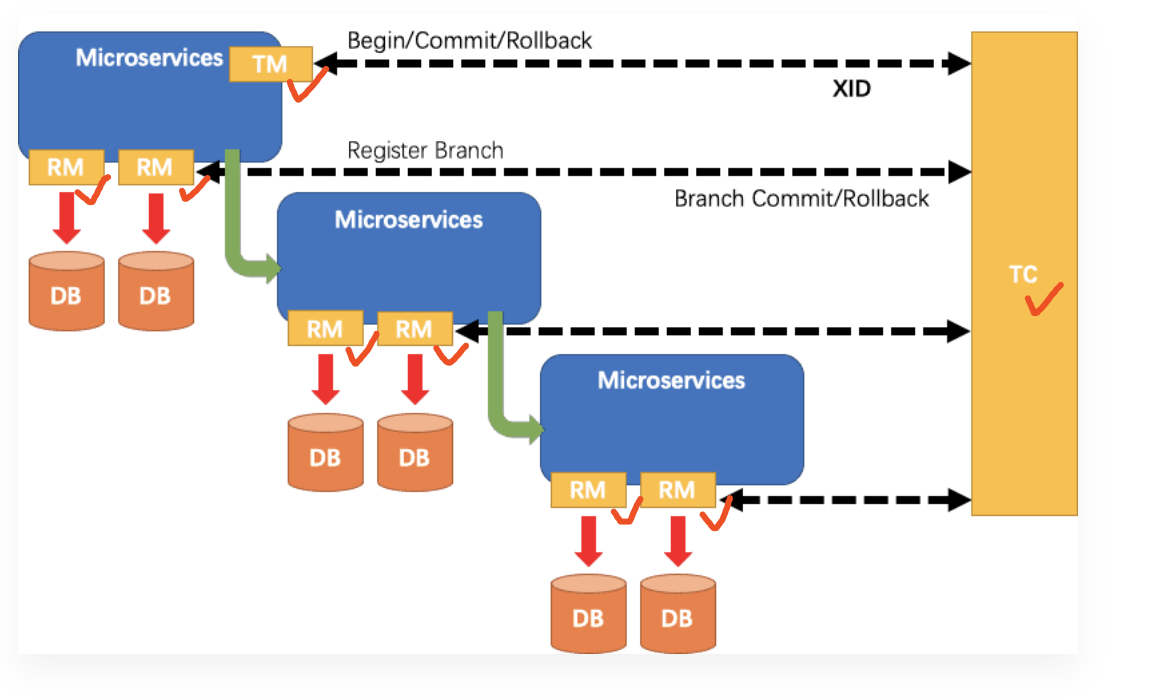
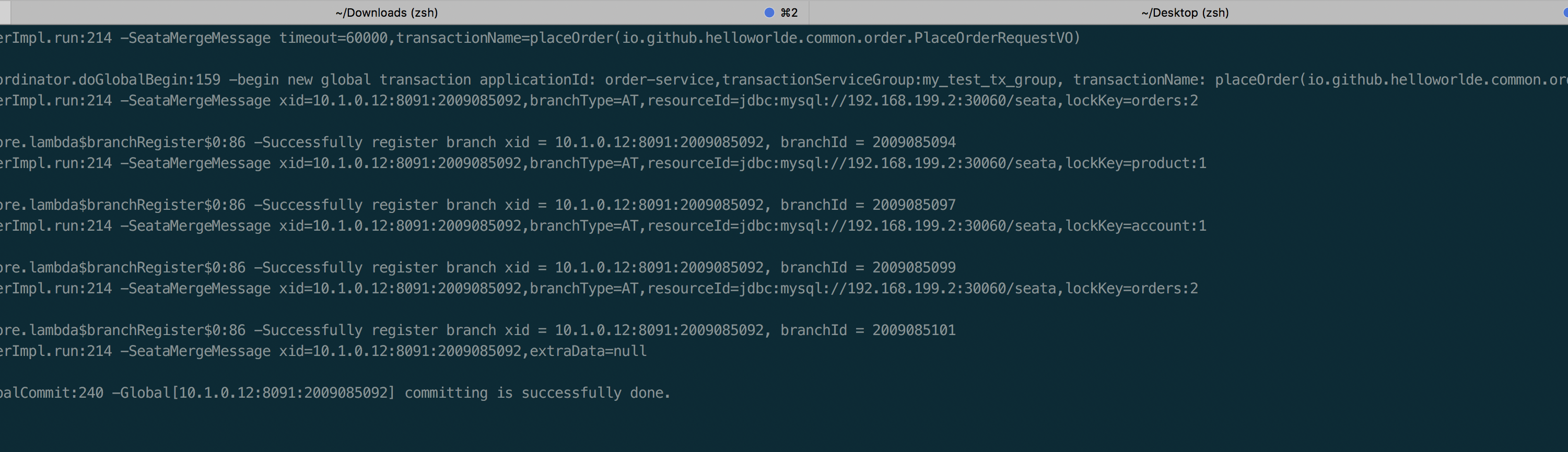
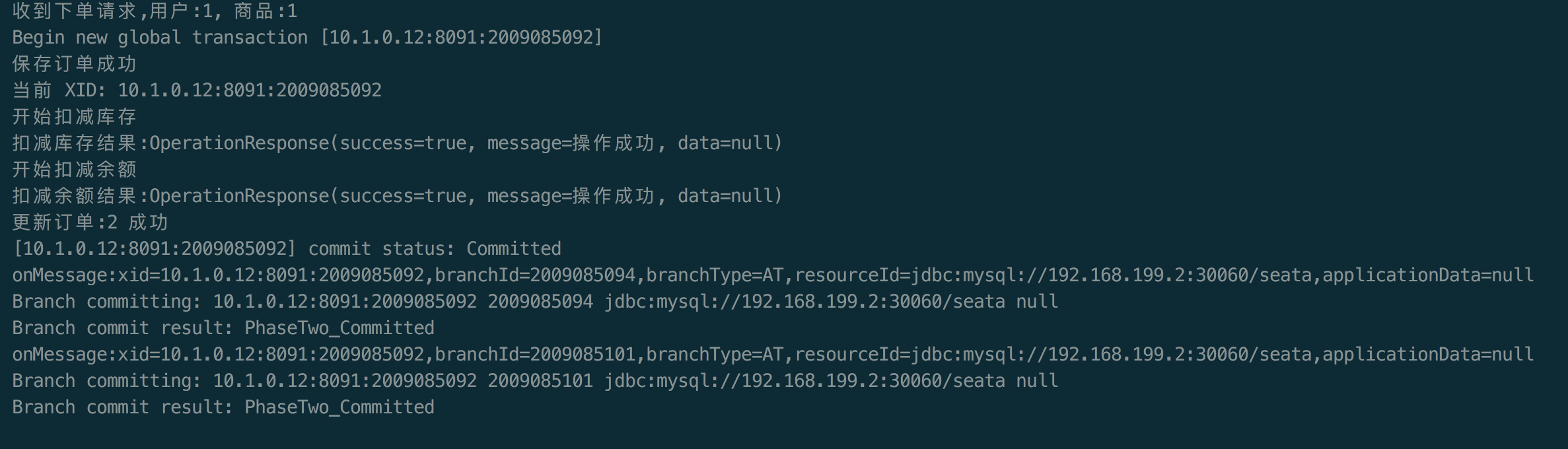
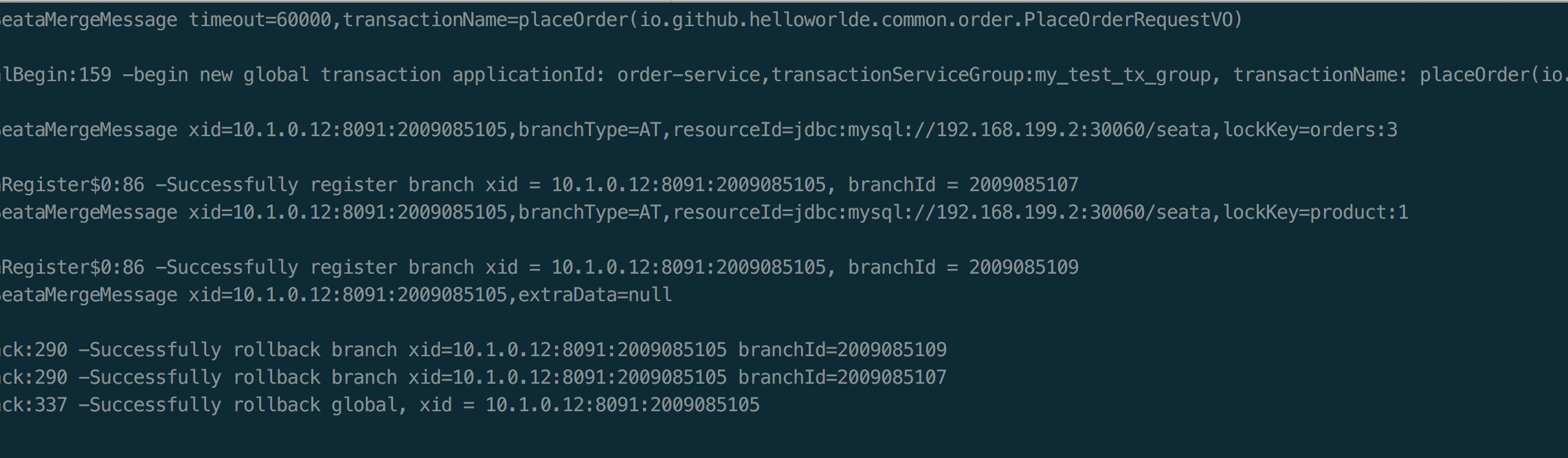
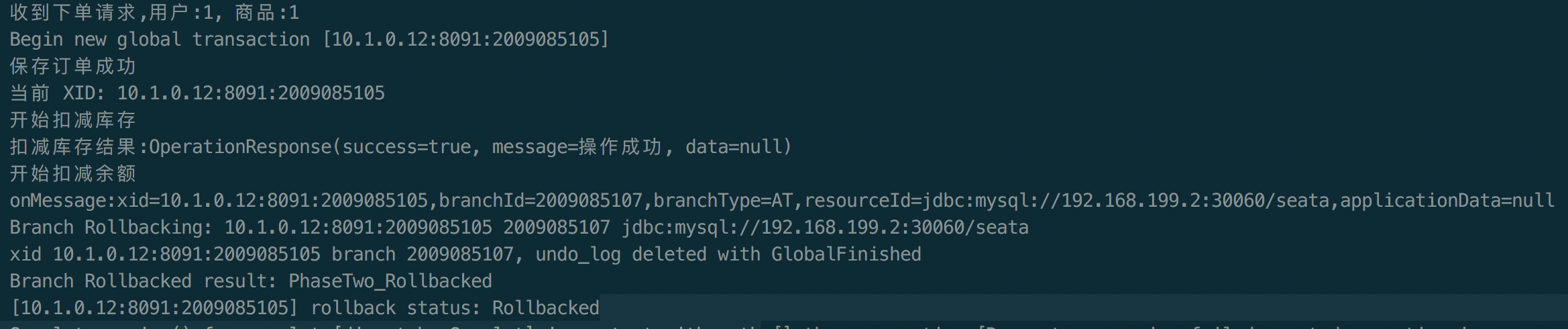
seata-golang 从今年 4 月份开始开发,到 8 月份基本实现和 java 版 seata 1.2 协议的互通,对 mysql 数据库实现了 AT 模式(自动协调分布式事务的提交回滚),实现了 TCC 模式,TC 端使用 mysql 存储数据,使 TC 变成一个无状态应用支持高可用部署。下图展示了 AT 模式的原理: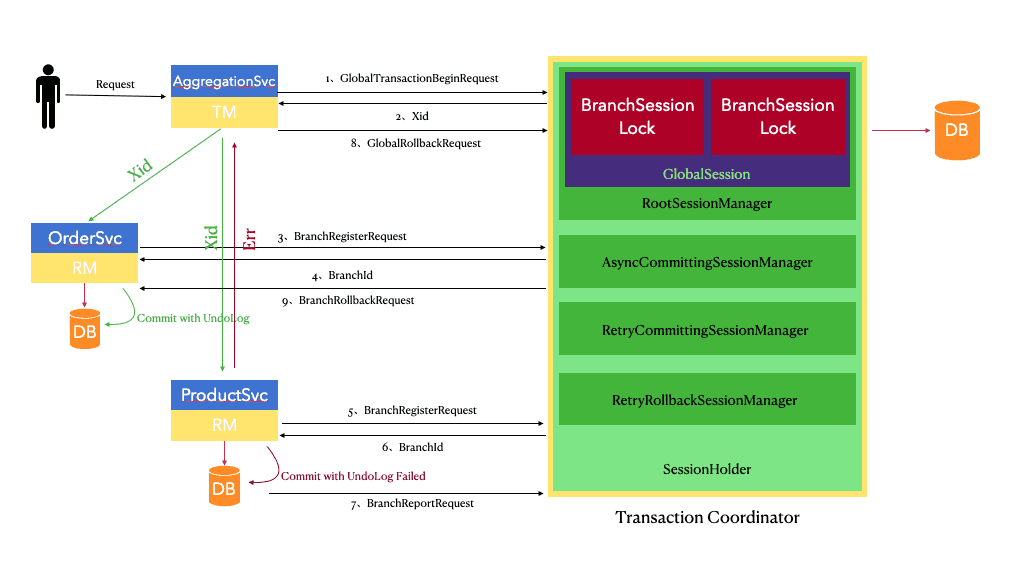
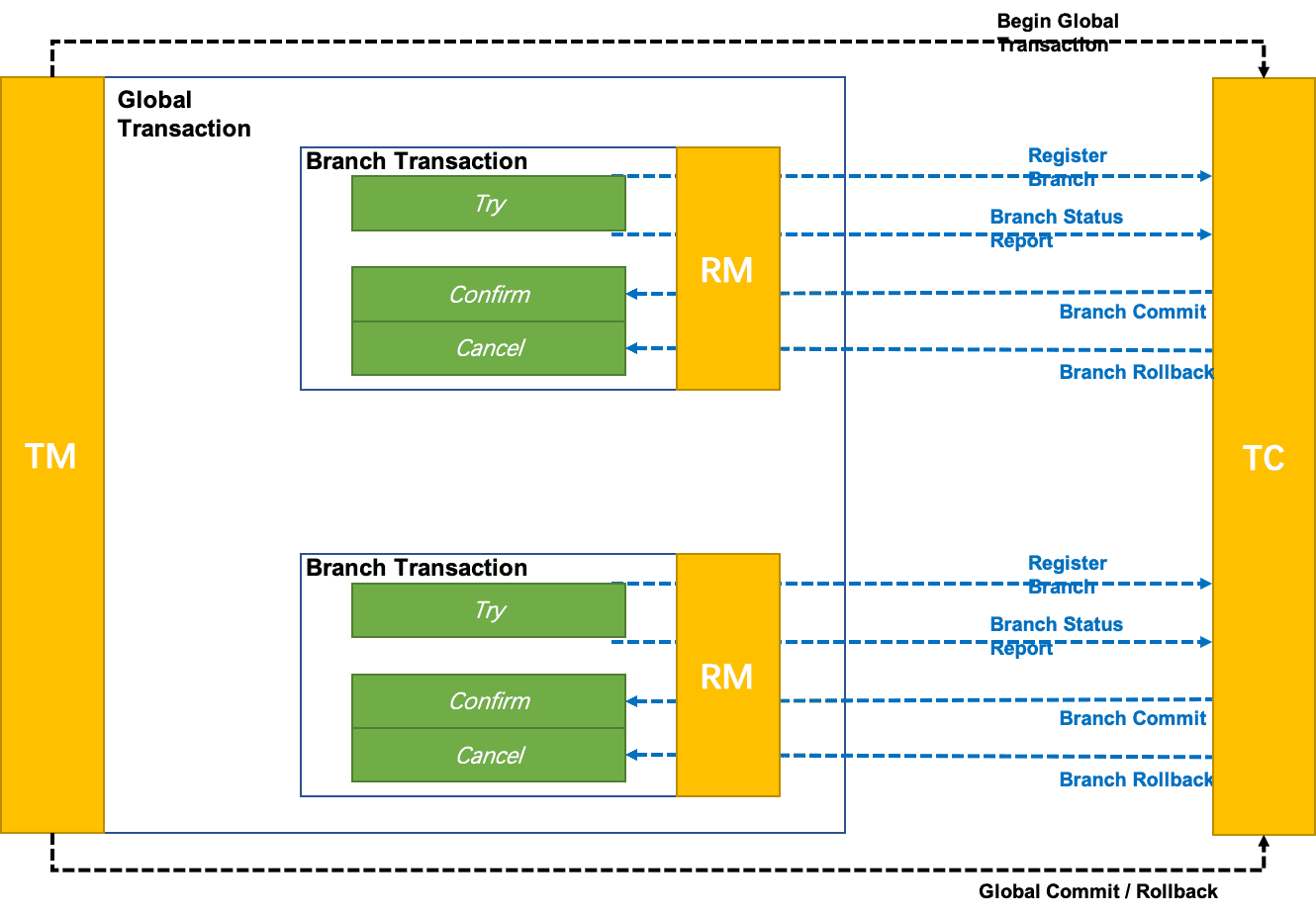
后续,还有许多工作可以做,比如:对注册中心的支持、对配置中心的支持、和 java 版 seata 1.4 的协议互通、其他数据库的支持、raft transaction coordinator 的实现等,希望对分布式事务问题感兴趣的开发者可以加入进来一起来打造一个完善的 golang 的分布式事务框架。
如果你有任何疑问,欢迎钉钉扫码加入交流群【钉钉群号 33069364】:

作者简介
刘晓敏 (GitHubID dk-lockdown),目前就职于 h3c 成都分公司,擅长使用 Java/Go 语言,在云原生和微服务相关技术方向均有涉猎,目前专攻分布式事务。 于雨(github @AlexStocks),dubbo-go 项目和社区负责人,一个有十多年服务端基础架构研发一线工作经验的程序员,陆续参与改进过 Muduo/Pika/Dubbo/Sentinel-go 等知名项目,目前在蚂蚁金服可信原生部从事容器编排和 service mesh 工作。
参考资料
seata 官方:https://seata.apache.org
java 版 seata:https://github.com/apache/incubator-seata
seata-golang 项目地址:https://github.com/apache/incubator-seata-go
seata-golang go 夜读 b站分享:https://www.bilibili.com/video/BV1oz411e72T
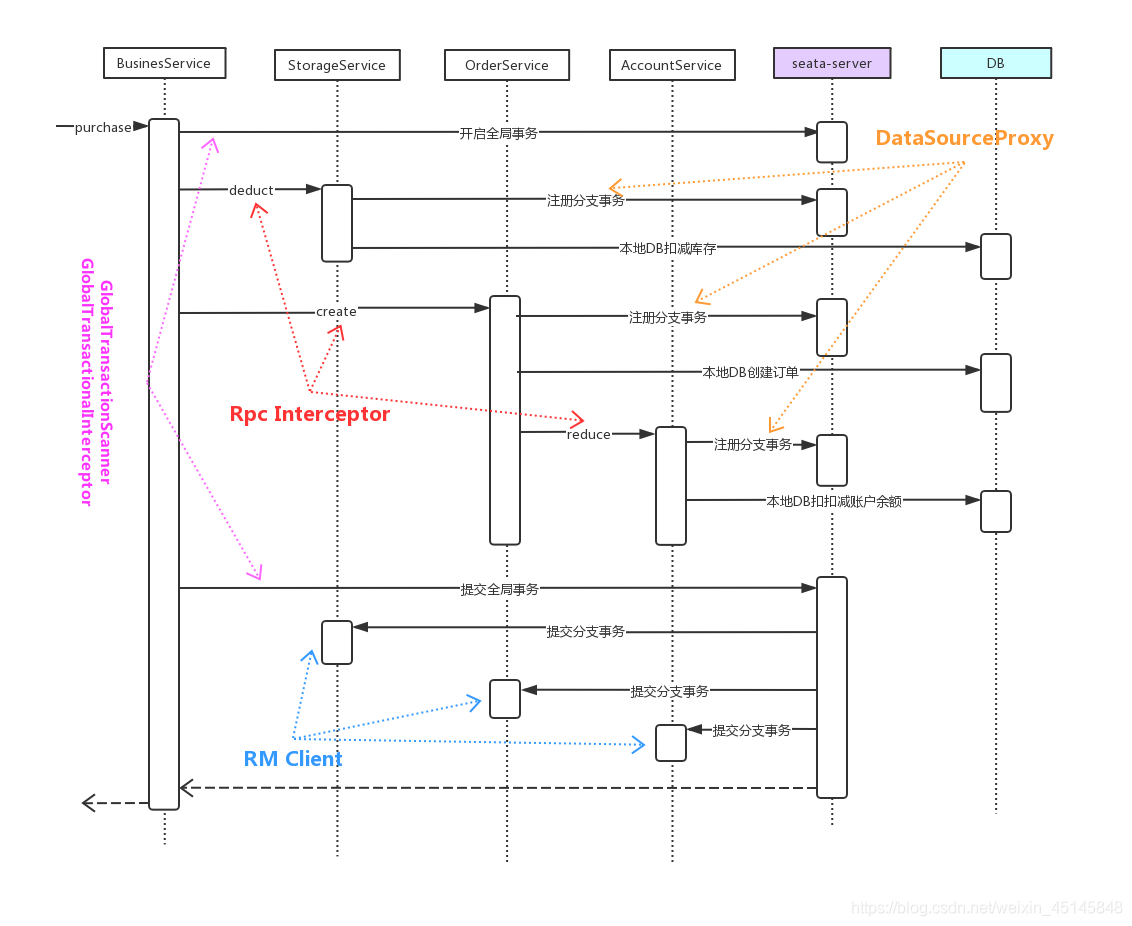
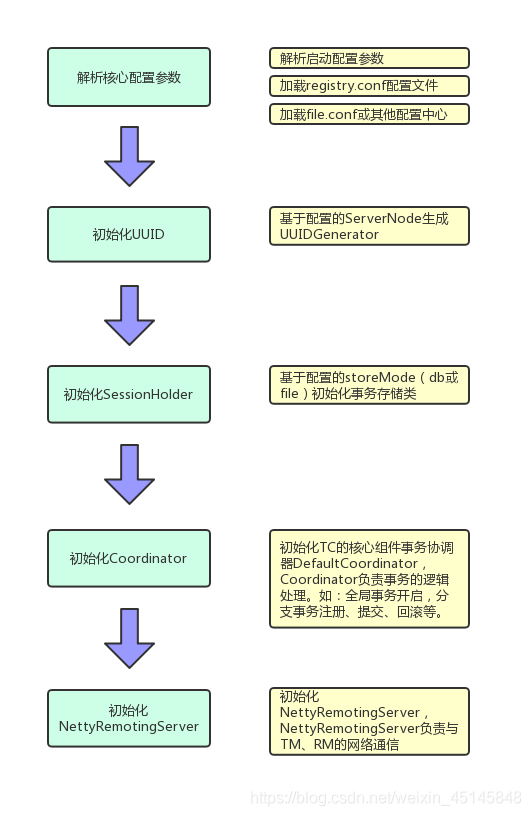
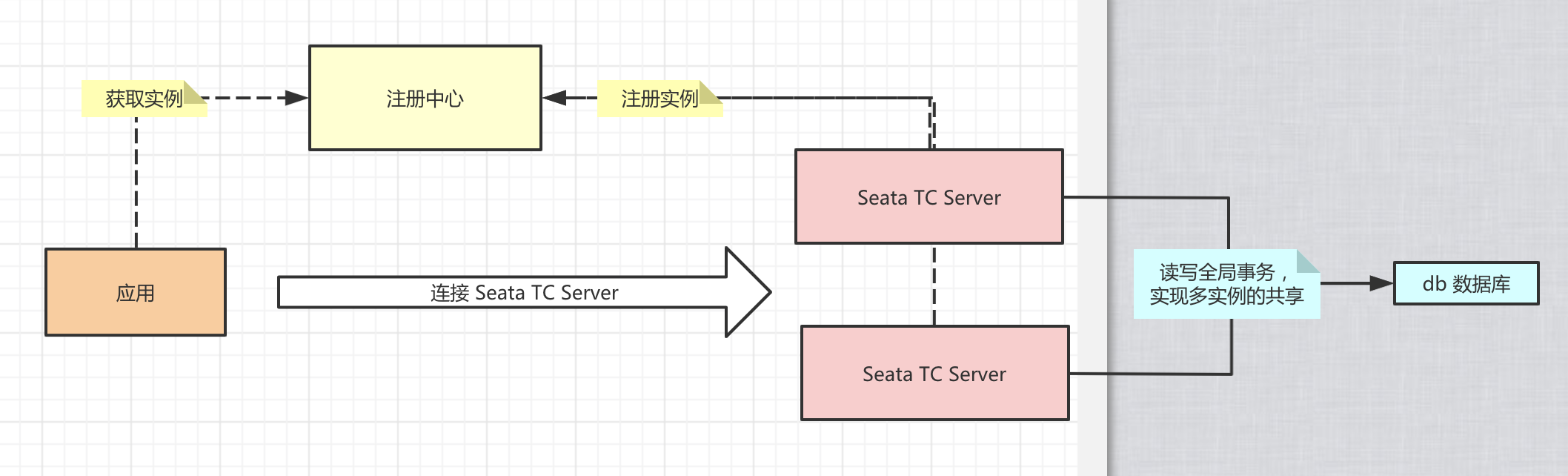
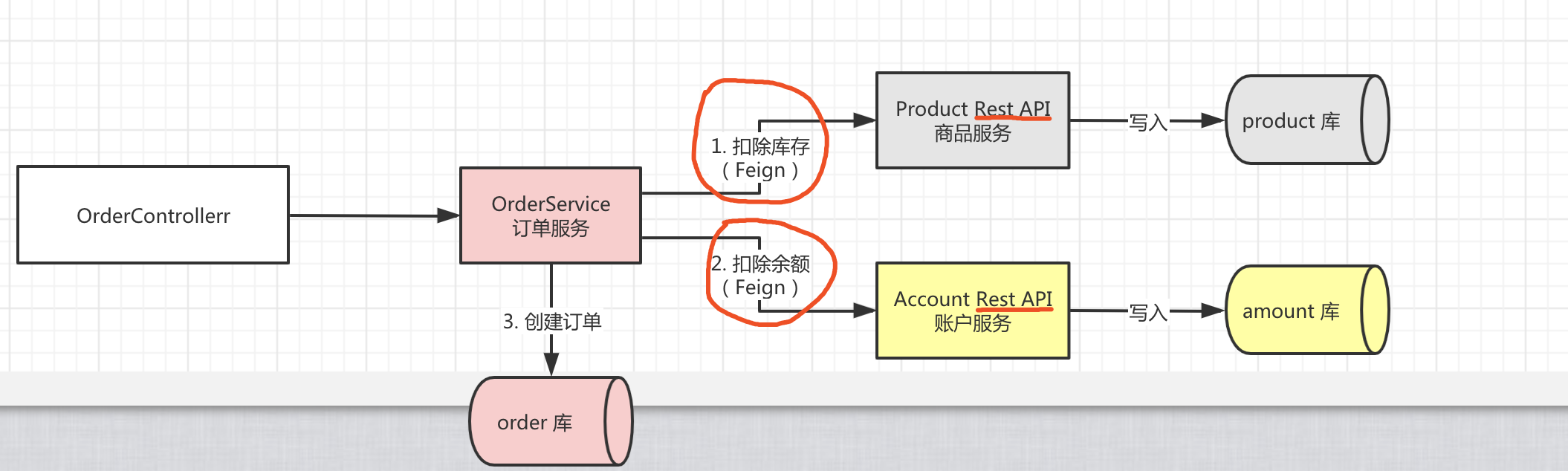
 主要分为以下几个模块:
主要分为以下几个模块:


















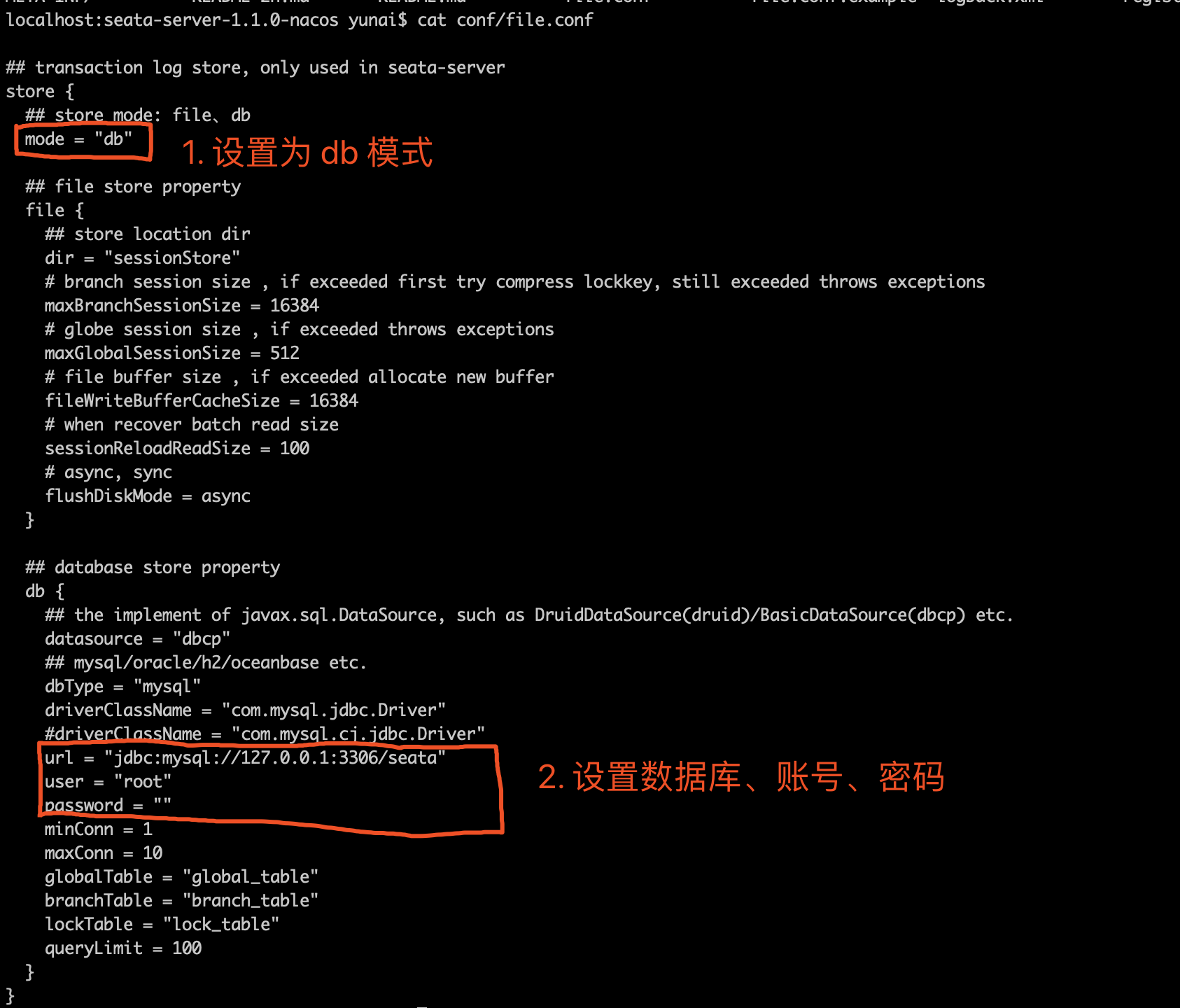
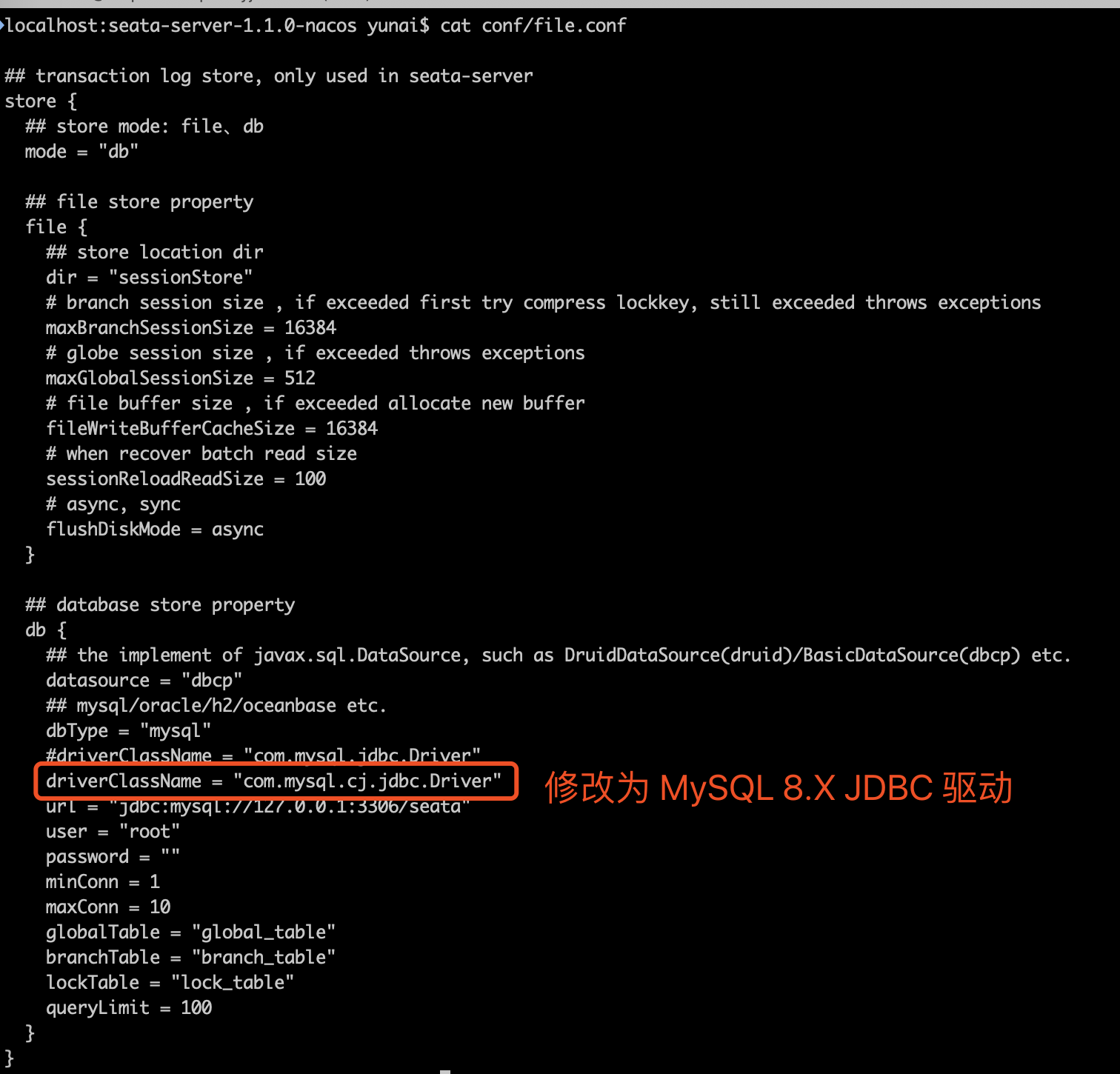
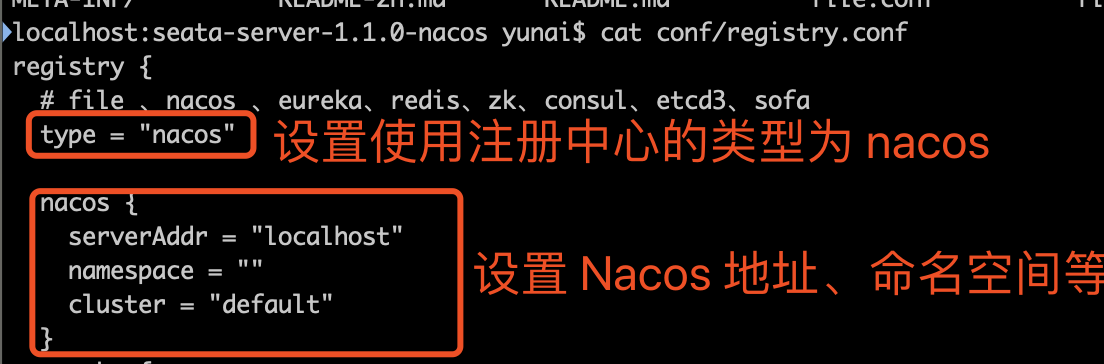


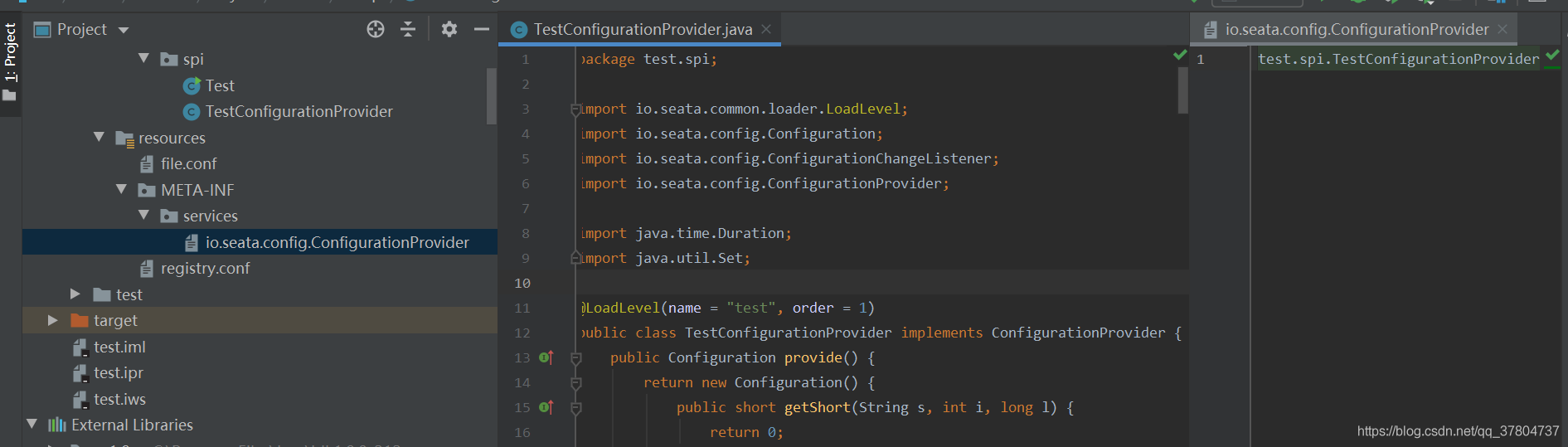 这是一个自定义配置中心提供类的例子,在 META-INF/services 下放置一个接口同名的文本文件,文件的内容为接口的实现类。这是标准的 spi 方式。然后修改配置文件 registry.conf 中的 config.type=test 。
这是一个自定义配置中心提供类的例子,在 META-INF/services 下放置一个接口同名的文本文件,文件的内容为接口的实现类。这是标准的 spi 方式。然后修改配置文件 registry.conf 中的 config.type=test 。 这里可以使用不优雅的方式,即提供一个指定名称 ZK 但是级别 order=3 更高的实现类(ZK 默认 order=1),就可以让 ConfigurationFactory 使用 TestConfigurationProvider 作为配置中心提供类。
这里可以使用不优雅的方式,即提供一个指定名称 ZK 但是级别 order=3 更高的实现类(ZK 默认 order=1),就可以让 ConfigurationFactory 使用 TestConfigurationProvider 作为配置中心提供类。