Seata currently supports AT mode, XA mode, TCC mode, and SAGA mode. Previous articles have talked more about non-intrusive AT mode. Today, we will introduce TCC mode, which is also a two-phase commit.
What is TCC
TCC is a two-phase commit protocol in distributed transactions. Its full name is Try-Confirm-Cancel. Their specific meanings are as follows:
- Try: Check and reserve business resources;
- Confirm: Commit the business transaction, i.e., the commit operation. If Try is successful, this step will definitely be successful;
- Cancel: Cancel the business transaction, i.e., the rollback operation. This step will release the resources reserved in Try.
TCC is an intrusive distributed transaction solution. All three operations need to be implemented by the business system itself, which has a significant impact on the business system. The design is relatively complex, but the advantage is that TCC does not rely on the database. It can manage resources across databases and applications, and can implement an atomic operation for different data access through intrusive coding, better solving the distributed transaction problems in various complex business scenarios.
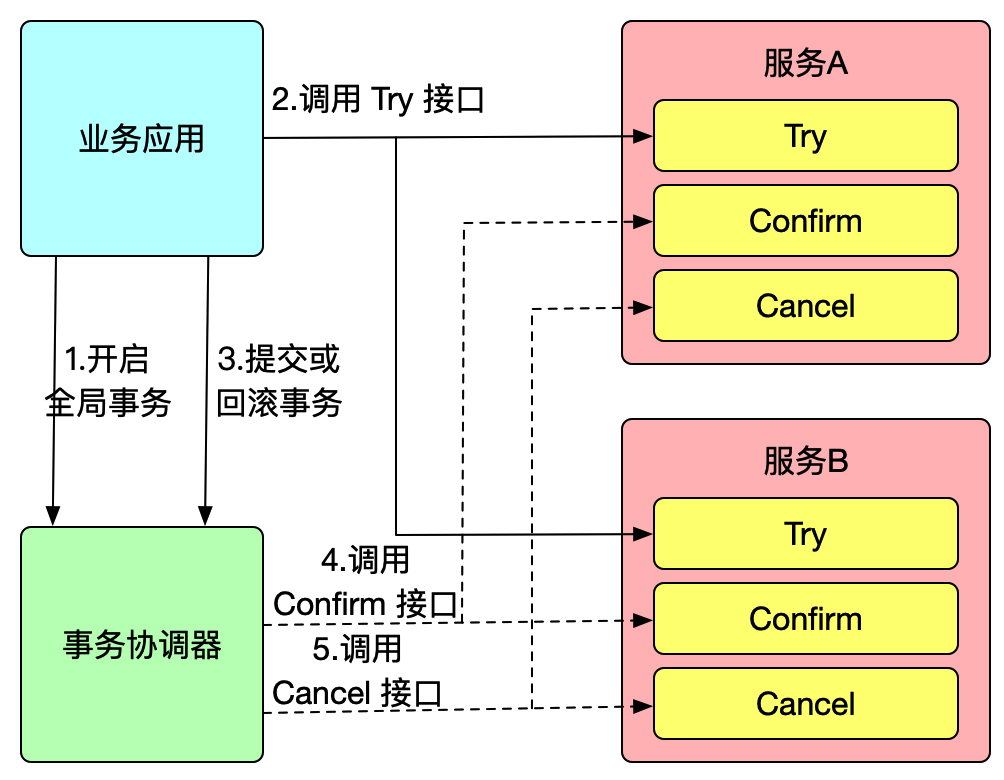
Seata TCC mode
Seata TCC mode follows the same principle as the general TCC mode. Let's first use Seata TCC mode to implement a distributed transaction:
Suppose there is a business that needs to use service A and service B to complete a transaction operation. We define a TCC interface for this service in service A:
public interface TccActionOne {
@TwoPhaseBusinessAction(name = "DubboTccActionOne", commitMethod = "commit", rollbackMethod = "rollback")
public boolean prepare(BusinessActionContext actionContext, @BusinessActionContextParameter(paramName = "a") String a);
public boolean commit(BusinessActionContext actionContext);
public boolean rollback(BusinessActionContext actionContext);
}
Similarly, we define a TCC interface for this service in service B:
public interface TccActionTwo {
@TwoPhaseBusinessAction(name = "DubboTccActionTwo", commitMethod = "commit", rollbackMethod = "rollback")
public void prepare(BusinessActionContext actionContext, @BusinessActionContextParameter(paramName = "b") String b);
public void commit(BusinessActionContext actionContext);
public void rollback(BusinessActionContext actionContext);
}
In the business system, we start a global transaction and execute the TCC reserve resource methods for service A and service B:
@GlobalTransactional
public String doTransactionCommit(){
// Service A transaction participant
tccActionOne.prepare(null,"one");
// Service B transaction participant
tccActionTwo.prepare(null,"two");
}
The example above demonstrates the implementation of a global transaction using Seata TCC mode. It can be seen that the TCC mode also uses the @GlobalTransactional annotation to initiate a global transaction, while the TCC interfaces of Service A and Service B are transaction participants. Seata treats a TCC interface as a Resource, also known as a TCC Resource.
TCC interfaces can be RPC or internal JVM calls, meaning that a TCC interface has both a sender and a caller identity. In the example above, the TCC interface is the sender in Service A and Service B, and the caller in the business system. If the TCC interface is a Dubbo RPC, the caller is a dubbo:reference and the sender is a dubbo:service.
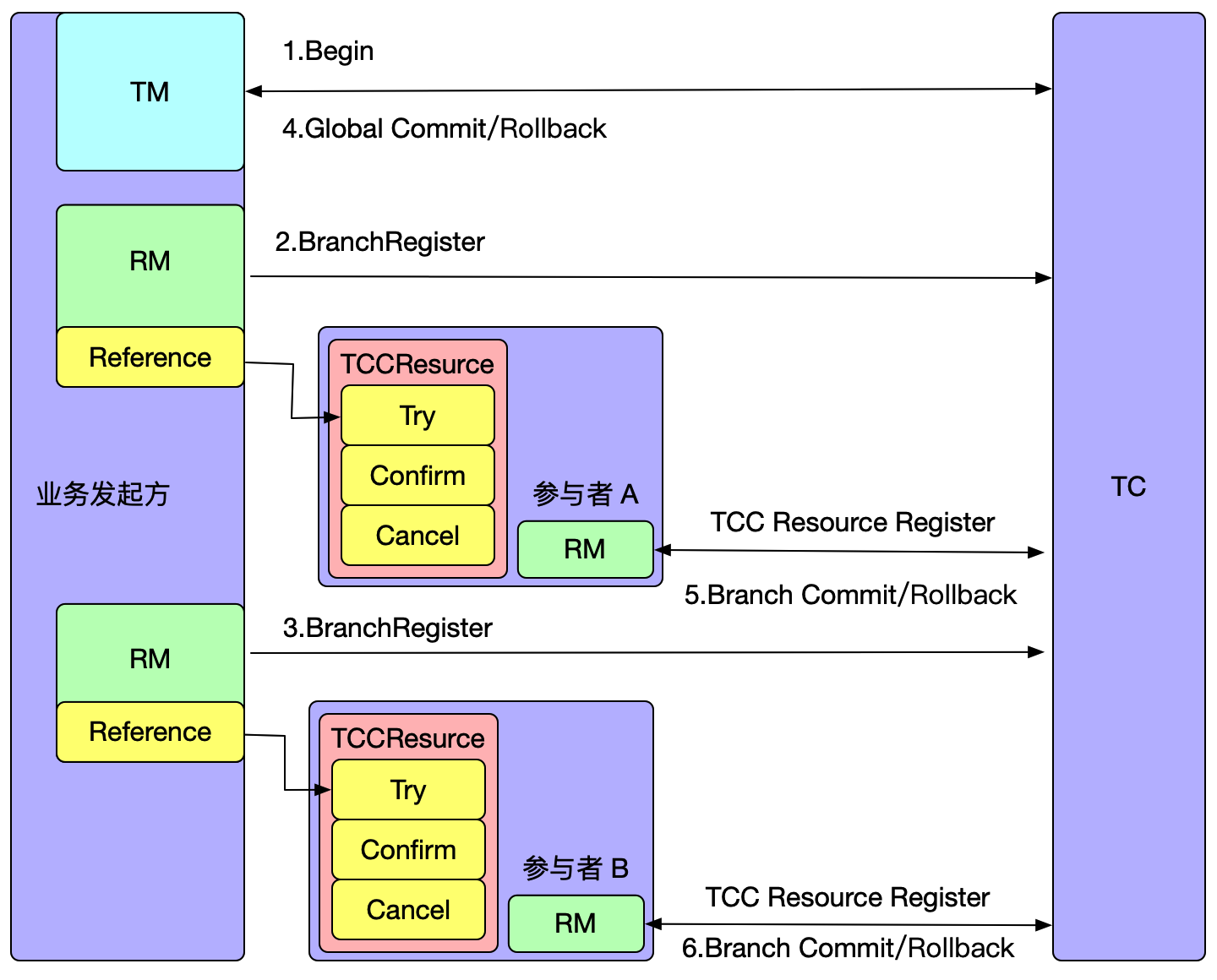
When Seata starts, it scans and parses the TCC interfaces. If a TCC interface is a sender, Seata registers the TCC Resource with the TC during startup, and each TCC Resource has a resource ID. If a TCC interface is a caller, Seata proxies the caller and intercepts the TCC interface calls. Similar to the AT mode, the proxy intercepts the call to the Try method, registers a branch transaction with the TC, and then executes the original RPC call.
When the global transaction decides to commit/rollback, the TC will callback to the corresponding participant service to execute the Confirm/Cancel method of the TCC Resource using the resource ID registered by the branch.
How Seata Implements TCC Mode
From the above Seata TCC model, it can be seen that the TCC mode in Seata also follows the TC, TM, RM three-role model. How to implement TCC mode in these three-role models? I mainly summarize the implementation as resource parsing, resource management, and transaction processing.
Resource Parsing
Resource parsing is the process of parsing and registering TCC interfaces. As mentioned earlier, TCC interfaces can be RPC or internal JVM calls. In the Seata TCC module, there is a remoting module that is specifically used to parse TCC interfaces with the TwoPhaseBusinessAction annotation:
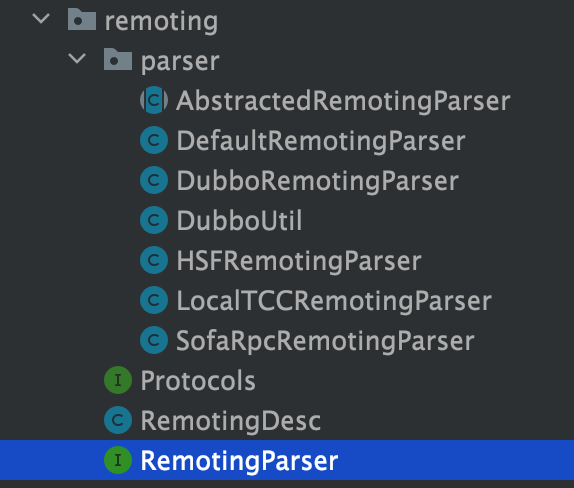
The RemotingParser interface mainly has methods such as isRemoting, isReference, isService, getServiceDesc, etc. The default implementation is DefaultRemotingParser, and the parsing of various RPC protocols is executed in DefaultRemotingParser. Seata has already implemented parsing of Dubbo, HSF, SofaRpc, and LocalTCC RPC protocols while also providing SPI extensibility for additional RPC protocol parsing classes.
During the Seata startup process, the GlobalTransactionScanner annotation is used for scanning and executes the following method:
io.seata.spring.util.TCCBeanParserUtils#isTccAutoProxy
The purpose of this method is to determine if the bean has been TCC proxied. In the process, it first checks if the bean is a Remoting bean. If it is, it calls the getServiceDesc method to parse the remoting bean, and if it is a sender, it registers the resource:
io.seata.rm.tcc.remoting.parser.DefaultRemotingParser#parserRemotingServiceInfo
public RemotingDesc parserRemotingServiceInfo(Object bean, String beanName, RemotingParser remotingParser){
RemotingDesc remotingBeanDesc = remotingParser.getServiceDesc(bean, beanName);
if(remotingBeanDesc == null){
return null;
}
remotingServiceMap.put(beanName, remotingBeanDesc);
Class<?> interfaceClass = remotingBeanDesc.getInterfaceClass();
Method[] methods = interfaceClass.getMethods();
if (remotingParser.isService(bean, beanName)) {
try {
//service bean, registry resource
Object targetBean = remotingBeanDesc.getTargetBean();
for (Method m : methods) {
TwoPhaseBusinessAction twoPhaseBusinessAction = m.getAnnotation(TwoPhaseBusinessAction.class);
if (twoPhaseBusinessAction != null) {
TCCResource tccResource = new TCCResource();
tccResource.setActionName(twoPhaseBusinessAction.name());
tccResource.setTargetBean(targetBean);
tccResource.setPrepareMethod(m);
tccResource.setCommitMethodName(twoPhaseBusinessAction.commitMethod());
tccResource.setCommitMethod(interfaceClass.getMethod(twoPhaseBusinessAction.commitMethod(),
twoPhaseBusinessAction.commitArgsClasses()));
tccResource.setRollbackMethodName(twoPhaseBusinessAction.rollbackMethod());
tccResource.setRollbackMethod(interfaceClass.getMethod(twoPhaseBusinessAction.rollbackMethod(),
twoPhaseBusinessAction.rollbackArgsClasses()));
// set argsClasses
tccResource.setCommitArgsClasses(twoPhaseBusinessAction.commitArgsClasses());
tccResource.setRollbackArgsClasses(twoPhaseBusinessAction.rollbackArgsClasses());
// set phase two method's keys
tccResource.setPhaseTwoCommitKeys(this.getTwoPhaseArgs(tccResource.getCommitMethod(),
twoPhaseBusinessAction.commitArgsClasses()));
tccResource.setPhaseTwoRollbackKeys(this.getTwoPhaseArgs(tccResource.getRollbackMethod(),
twoPhaseBusinessAction.rollbackArgsClasses()));
// registry tcc resource
DefaultResourceManager.get().registerResource(tccResource);
}
}
} catch (Throwable t) {
throw new FrameworkException(t, "parser remoting service error");
}
}
if (remotingParser.isReference(bean, beanName)) {
// reference bean, TCC proxy
remotingBeanDesc.setReference(true);
}
return remotingBeanDesc;
}
The above method first calls the parsing class getServiceDesc method to parse the remoting bean and puts the parsed remotingBeanDesc into the local cache remotingServiceMap. At the same time, it calls the parsing class isService method to determine if it is the initiator. If it is the initiator, it parses the content of the TwoPhaseBusinessAction annotation to generate a TCCResource and registers it as a resource.
Resource Management
1. Resource Registration
The resource for Seata TCC mode is called TCCResource, and its resource manager is called TCCResourceManager. As mentioned earlier, after parsing the TCC interface RPC resource, if it is the initiator, it will be registered as a resource:
io.seata.rm.tcc.TCCResourceManager#registerResource
public void registerResource(Resource resource){
TCCResource tccResource=(TCCResource)resource;
tccResourceCache.put(tccResource.getResourceId(),tccResource);
super.registerResource(tccResource);
}
TCCResource contains the relevant information of the TCC interface and is cached locally. It continues to call the parent class registerResource method (which encapsulates communication methods) to register with the TC. The TCC resource's resourceId is the actionName, and the actionName is the name in the @TwoParseBusinessAction annotation.
2. Resource Commit/Rollback
io.seata.rm.tcc.TCCResourceManager#branchCommit
public BranchStatus branchCommit(BranchType branchType,String xid,long branchId,String resourceId,
String applicationData)throws TransactionException{
TCCResource tccResource=(TCCResource)tccResourceCache.get(resourceId);
if(tccResource==null){
throw new ShouldNeverHappenException(String.format("TCC resource is not exist, resourceId: %s",resourceId));
}
Object targetTCCBean=tccResource.getTargetBean();
Method commitMethod=tccResource.getCommitMethod();
if(targetTCCBean==null||commitMethod==null){
throw new ShouldNeverHappenException(String.format("TCC resource is not available, resourceId: %s",resourceId));
}
try{
//BusinessActionContext
BusinessActionContext businessActionContext=getBusinessActionContext(xid,branchId,resourceId,
applicationData);
// ... ...
ret=commitMethod.invoke(targetTCCBean,args);
// ... ...
return result?BranchStatus.PhaseTwo_Committed:BranchStatus.PhaseTwo_CommitFailed_Retryable;
}catch(Throwable t){
String msg=String.format("commit TCC resource error, resourceId: %s, xid: %s.",resourceId,xid);
LOGGER.error(msg,t);
return BranchStatus.PhaseTwo_CommitFailed_Retryable;
}
}
When the TM resolves the phase two commit, the TC will callback to the corresponding participant (i.e., TCC interface initiator) service to execute the Confirm/Cancel method of the TCC Resource registered by the branch.
In the resource manager, the corresponding TCCResource will be found in the local cache based on the resourceId, and the corresponding BusinessActionContext will be found based on xid, branchId, resourceId, and applicationData, and the parameters to be executed are in the context. Finally, the commit method of the TCCResource is executed to perform the phase two commit.
The phase two rollback is similar.
Transaction Processing
As mentioned earlier, if the TCC interface is a caller, the Seata TCC proxy will be used to intercept the caller and register the branch before processing the actual RPC method call.
The method io.seata.spring.util.TCCBeanParserUtils#isTccAutoProxy not only parses the TCC interface resources, but also determines whether the TCC interface is a caller. If it is a caller, it returns true:
io.seata.spring.annotation.GlobalTransactionScanner#wrapIfNecessary

As shown in the figure, when GlobalTransactionalScanner scans the TCC interface caller (Reference), it will proxy and intercept it with TccActionInterceptor, which implements MethodInterceptor.
In TccActionInterceptor, it will also call ActionInterceptorHandler to execute the interception logic, and the transaction-related processing is in the ActionInterceptorHandler#proceed method:
public Object proceed(Method method, Object[] arguments, String xid, TwoPhaseBusinessAction businessAction,
Callback<Object> targetCallback) throws Throwable {
//Get action context from arguments, or create a new one and then reset to arguments
BusinessActionContext actionContext = getOrCreateActionContextAndResetToArguments(method.getParameterTypes(), arguments);
//Creating Branch Record
String branchId = doTccActionLogStore(method, arguments, businessAction, actionContext);
// ... ...
try {
// ... ...
return targetCallback.execute();
} finally {
try {
//to report business action context finally if the actionContext.getUpdated() is true
BusinessActionContextUtil.reportContext(actionContext);
} finally {
// ... ...
}
}
}
In the process of executing the first phase of the TCC interface, the doTccActionLogStore method is called for branch registration, and the TCC-related information such as parameters is placed in the context. This context will be used for resource submission/rollback as mentioned above.
How to control exceptions
In the process of executing the TCC model, various exceptions may occur, the most common of which are empty rollback, idempotence, and suspense. Here I will explain how Seata handles these three types of exceptions.
How to handle empty rollback
What is an empty rollback?
An empty rollback refers to a situation in a distributed transaction where the TM drives the second-phase rollback of the participant's Cancel method without calling the participant's Try method.
How does an empty rollback occur?
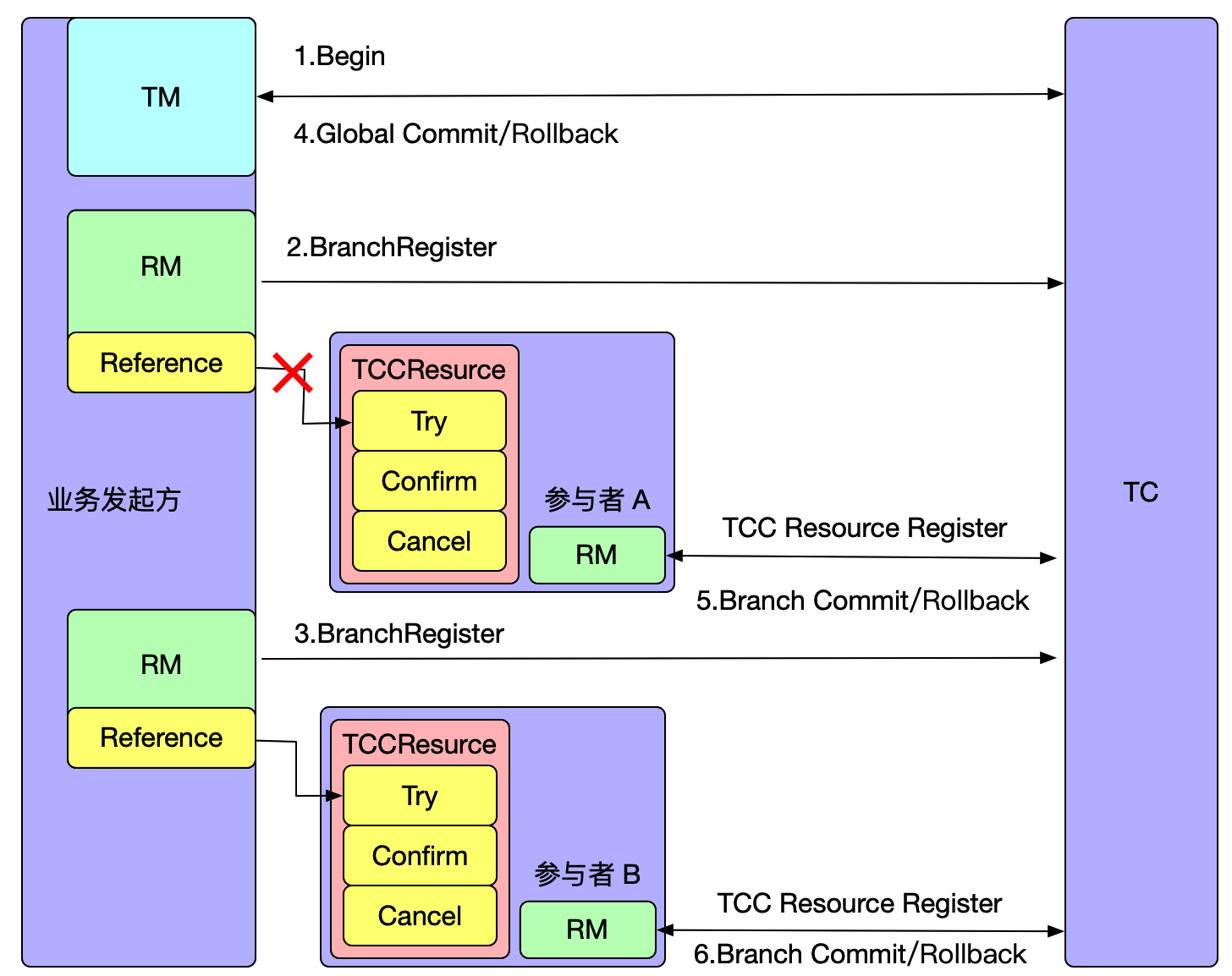
As shown in the above figure, after the global transaction is opened, participant A will execute the first-phase RPC method after completing branch registration. If the machine where participant A is located crashes or there is a network anomaly at this time, the RPC call will fail, meaning that participant A's first-phase method did not execute successfully. However, the global transaction has already been opened, so Seata must progress to the final state. When the global transaction is rolled back, participant A's Cancel method will be called, resulting in an empty rollback.
To prevent empty rollback, it is necessary to identify it in the Cancel method. How does Seata do this?
Seata's approach is to add a TCC transaction control table, which contains the XID and BranchID information of the transaction. A record is inserted when the Try method is executed, indicating that phase one has been executed. When the Cancel method is executed, this record is read. If the record does not exist, it means that the Try method was not executed.
How to Handle Idempotent Operations
Idempotent operation refers to TC repeating the two-phase commit, so the Confirm/Cancel interface needs to support idempotent processing, which means that it will not cause duplicate resource submission or release.
So how does idempotent operation arise?
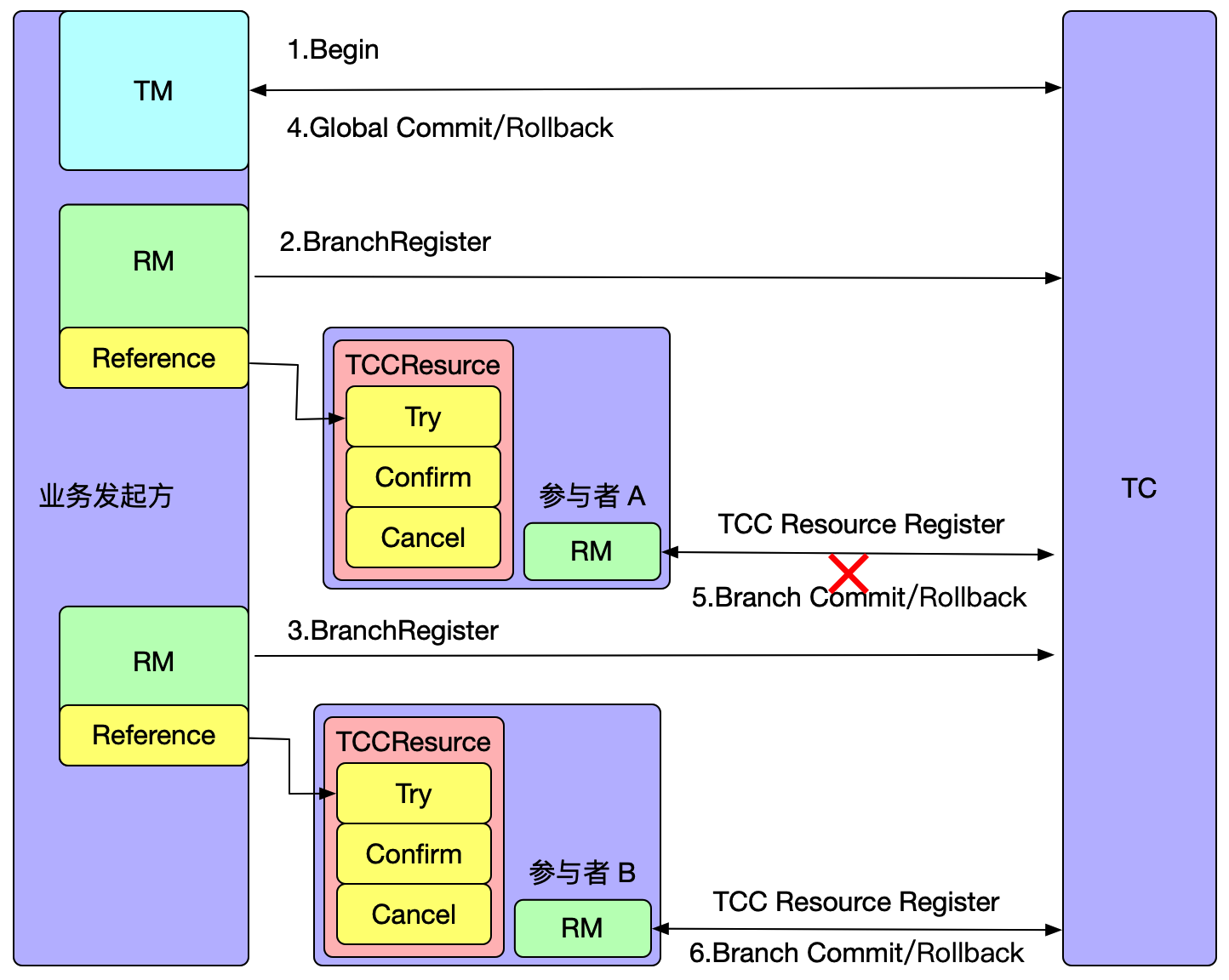
As shown in the above figure, after participant A completes the two phases, network jitter or machine failure may cause TC not to receive the return result of participant A's execution of the two phases. TC will continue to make repeated calls until the two-phase execution result is successful.
How does Seata handle idempotent operations?
Similarly, a status field is added to the TCC transaction control table. This field has 3 values:
- tried: 1
- committed: 2
- rollbacked: 3
After the execution of the two-phase Confirm/Cancel method, the status is changed to committed or rollbacked. When the two-phase Confirm/Cancel method is called repeatedly, checking the transaction status can solve the idempotent problem.
How to Handle Suspend
Suspension refers to the two-phase Cancel method being executed before the phase Try method, because empty rollback is allowed. After the execution of the two-phase Cancel method, directly returning success, the global transaction has ended. However, because the Try method is executed later, this will cause the resources reserved by the phase Try method to never be committed or released.
So how does suspension arise?
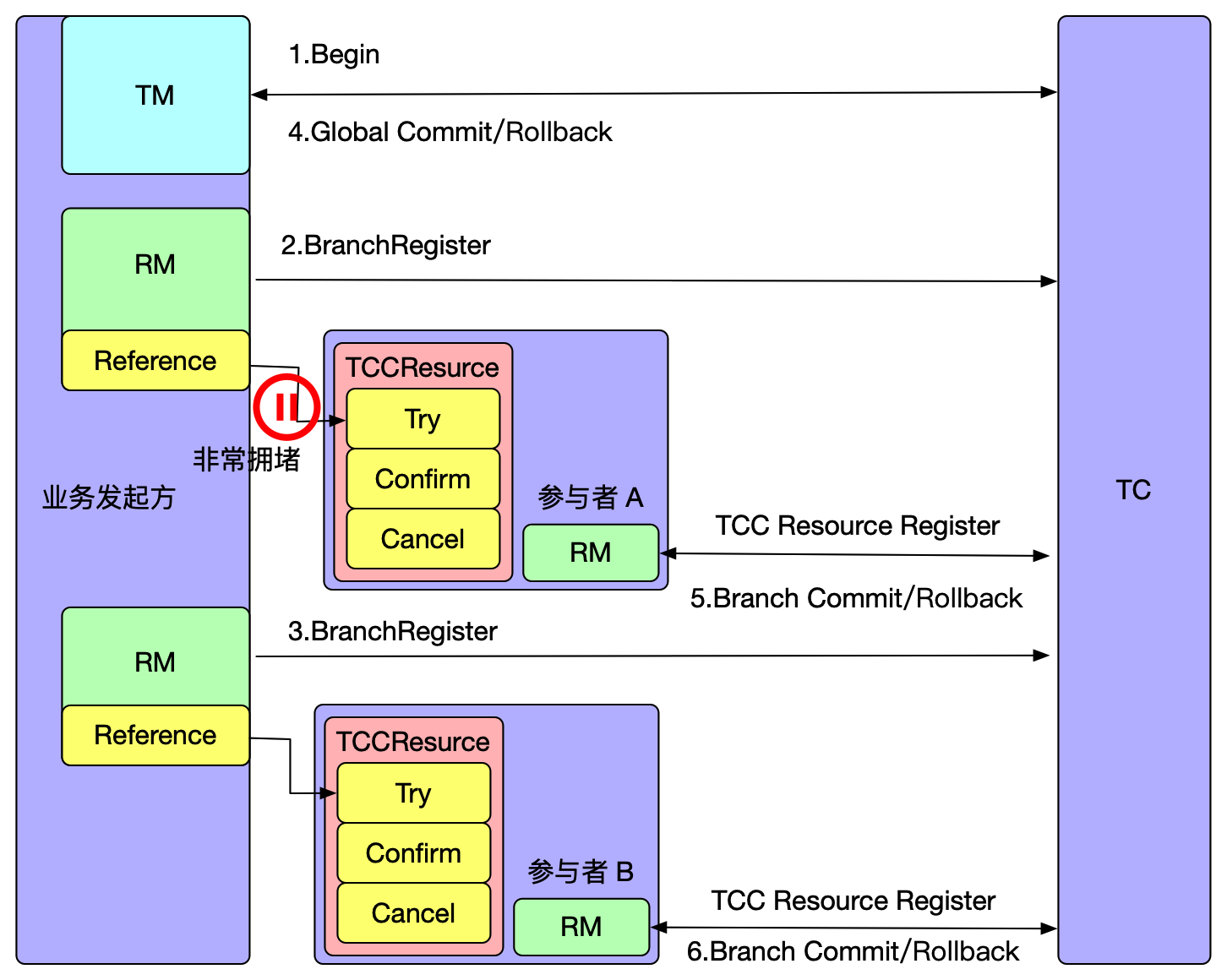
As shown in the above figure, when participant A's phase Try method is executed, network congestion occurs, and due to Seata's global transaction timeout limit, after the Try method times out, TM resolves to roll back the global transaction. After the rollback is completed, if the RPC request arrives at participant A at this time and the Try method is executed to reserve resources, it will cause suspension.
How does Seata handle suspension?
Add a status to the TCC transaction control table:
- suspended: 4
When the two-phase Cancel method is executed, if it is found that there is no related record in the TCC transaction control table, it means that the two-phase Cancel method is executed before the phase Try method. Therefore, a record with status=4 is inserted. Then, when the phase Try method is executed, if status=4 is encountered, it means that the two-phase Cancel has been executed, and false is returned to prevent the phase Try method from succeeding.
Author Introduction
Zhang Chenghui, currently working at Ant Group, loves to share technology. He is the author of the WeChat public account "Advanced Backend," the author of the technical blog (https://objcoding.com/), and his GitHub ID is: objcoding.





 to:
to:

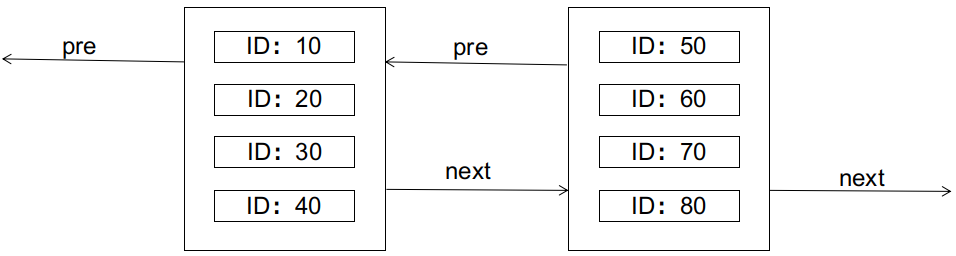 The characteristics of the B+ tree require that the left node should be smaller than the right node. What happens if we want to insert a record with an ID of 25 at this point (assuming each data page can only hold 4 records)? The answer is that it will cause a page split, as shown in the diagram:
The characteristics of the B+ tree require that the left node should be smaller than the right node. What happens if we want to insert a record with an ID of 25 at this point (assuming each data page can only hold 4 records)? The answer is that it will cause a page split, as shown in the diagram:
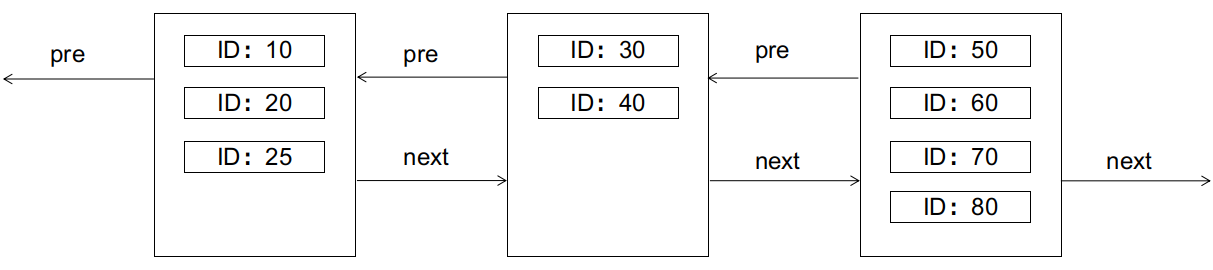 Page splits are unfriendly to I/O, requiring the creation of new data pages, copying and transferring part of the records from the old data page, etc., and should be avoided as much as possible.
Page splits are unfriendly to I/O, requiring the creation of new data pages, copying and transferring part of the records from the old data page, etc., and should be avoided as much as possible.