Seata 目前支持 AT 模式、XA 模式、TCC 模式和 SAGA 模式,之前文章更多谈及的是非侵入式的 AT 模式,今天带大家认识一下同样是二阶段提交的 TCC 模式。
什么是 TCC
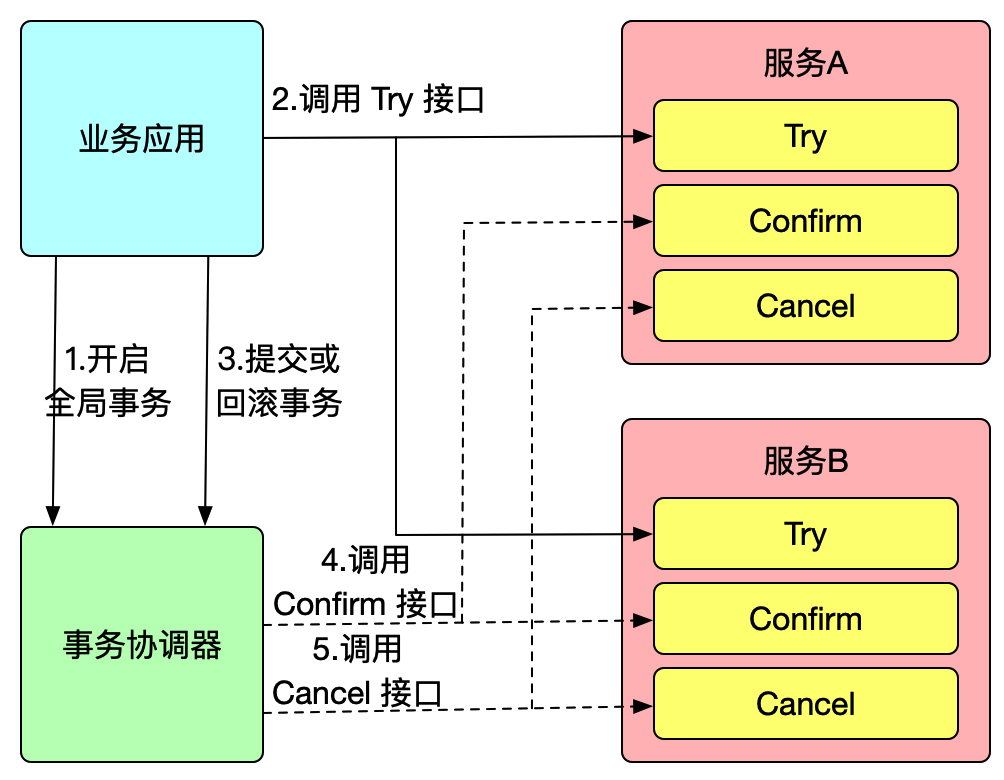
TCC 是分布式事务中的二阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel),他们的具体含义如下:
- Try:对业务资源的检查并预留;
- Confirm:对业务处理进行提交,即 commit 操作,只要 Try 成功,那么该步骤一定成功;
- Cancel:对业务处理进行取消,即回滚操作,该步骤回对 Try 预留的资源进行释放。
TCC 是一种侵入式的分布式事务解决方案,以上三个操作都需要业务系统自行实现,对业务系统有着非常大的入侵性,设计相对复杂,但优点是 TCC 完全不依赖数据库,能够实现跨数据库、跨应用资源管理,对这些不同数据访问通过侵入式的编码方式实现一个原子操作,更好地解决了在各种复杂业务场景下的分布式事务问题。
Seata TCC 模式
Seata TCC 模式跟通用型 TCC 模式原理一致,我们先来使用 Seata TCC 模式实现一个分布式事务:
假设现有一个业务需要同时使用服务 A 和服务 B 完成一个事务操作,我们在服务 A 定义该服务的一个 TCC 接口:
public interface TccActionOne {
@TwoPhaseBusinessAction(name = "DubboTccActionOne", commitMethod = "commit", rollbackMethod = "rollback")
public boolean prepare(BusinessActionContext actionContext, @BusinessActionContextParameter(paramName = "a") String a);
public boolean commit(BusinessActionContext actionContext);
public boolean rollback(BusinessActionContext actionContext);
}
同样,在服务 B 定义该服务的一个 TCC 接口:
public interface TccActionTwo {
@TwoPhaseBusinessAction(name = "DubboTccActionTwo", commitMethod = "commit", rollbackMethod = "rollback")
public void prepare(BusinessActionContext actionContext, @BusinessActionContextParameter(paramName = "b") String b);
public void commit(BusinessActionContext actionContext);
public void rollback(BusinessActionContext actionContext);
}
在业务所在系统中开启全局事务并执行服务 A 和服务 B 的 TCC 预留资源方法:
@GlobalTransactional
public String doTransactionCommit(){
//服务A事务参与者
tccActionOne.prepare(null,"one");
//服务B事务参与者
tccActionTwo.prepare(null,"two");
}
以上就是使用 Seata TCC 模式实现一个全局事务的例子,可以看出,TCC 模式同样使用 @GlobalTransactional 注解开启全局事务,而服务 A 和服务 B 的 TCC 接口为事务参与者,Seata 会把一个 TCC
接口当成一个 Resource,也叫 TCC Resource。
TCC 接口可以是 RPC,也可以是 JVM 内部调用,意味着一个 TCC 接口,会有发起方和调用方两个身份,以上例子,TCC 接口在服务 A 和服务 B 中是发起方,在业务所在系统中是调用方。如果该 TCC 接口为 Dubbo RPC,那么调用方就是一个 dubbo:reference,发起方则是一个 dubbo:service。
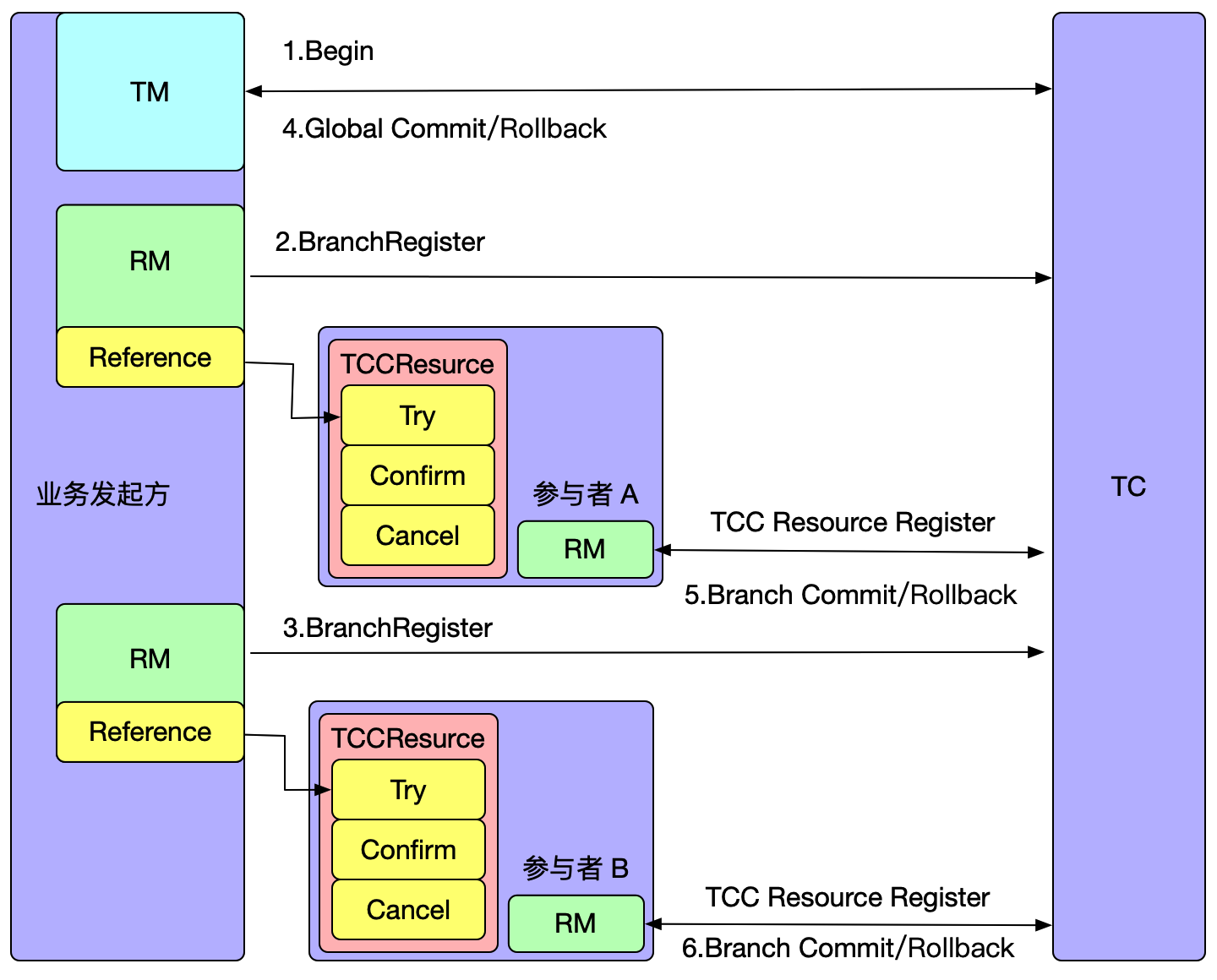
Seata 启动时会对 TCC 接口进行扫描并解析,如果 TCC 接口是一个发布方,则在 Seata 启动时会向 TC 注册 TCC Resource,每个 TCC Resource 都有一个资源 ID;如果 TCC 接口时一个调用方,Seata 代理调用方,与 AT 模式一样,代理会拦截 TCC 接口的调用,即每次调用 Try 方法,会向 TC 注册一个分支事务,接着才执行原来的 RPC 调用。
当全局事务决议提交/回滚时,TC 会通过分支注册的的资源 ID 回调到对应参与者服务中执行 TCC Resource 的 Confirm/Cancel 方法。
Seata 如何实现 TCC 模式
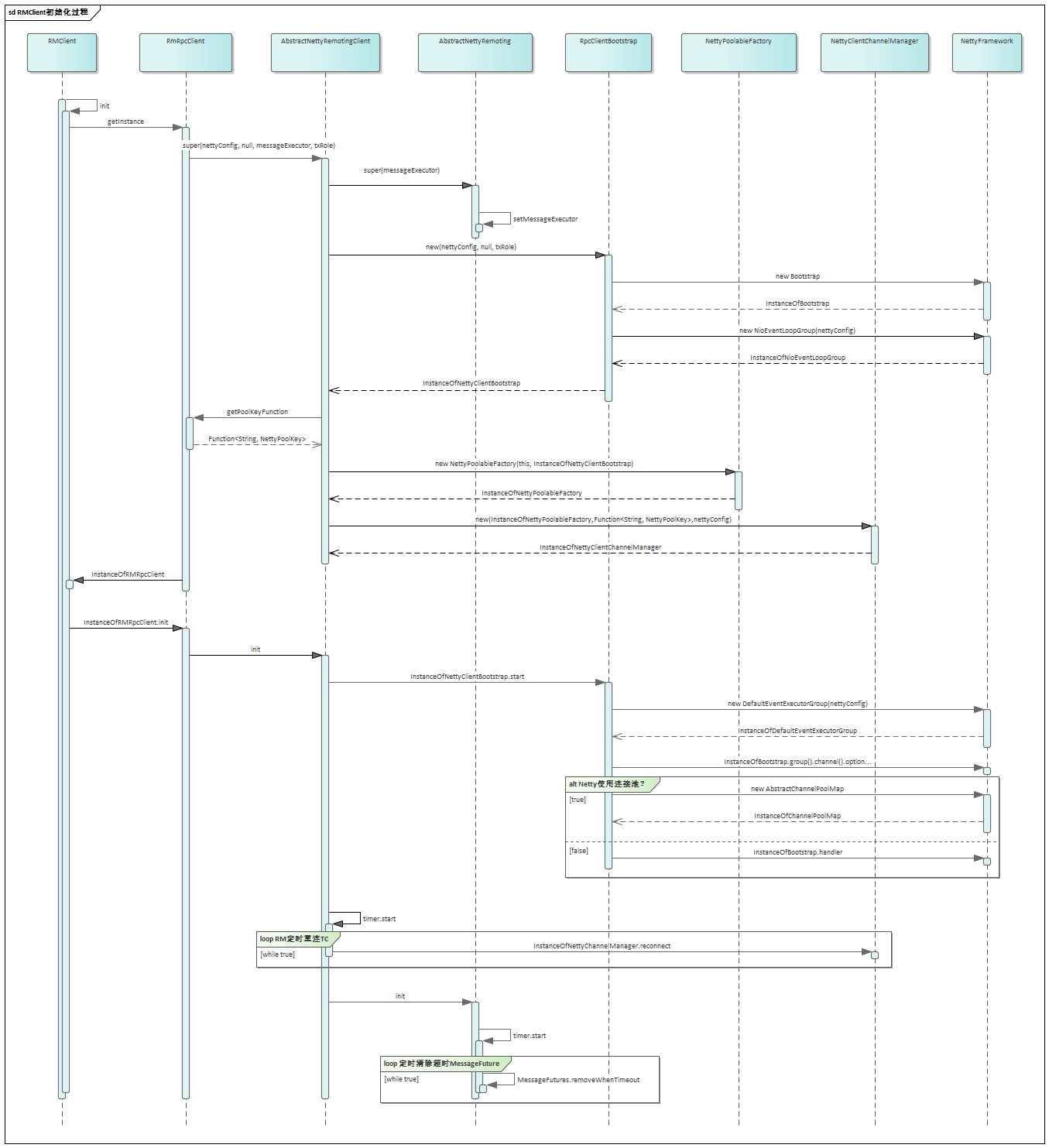
从上面的 Seata TCC 模型可以看出,TCC 模式在 Seata 中也是遵循 TC、TM、RM 三种角色模型的,如何在这三种角色模型中实现 TCC 模式呢?我将其主要实现归纳为资源解析、资源管理、事务处理。
资源�解析
资源解析即是把 TCC 接口进行解析并注册,前面说过,TCC 接口可以是 RPC,也可以是 JVM 内部调用,在 Seata TCC 模块有中一个 remoting
模块,该模块专门用于解析具有 TwoPhaseBusinessAction 注解的 TCC 接口资源:
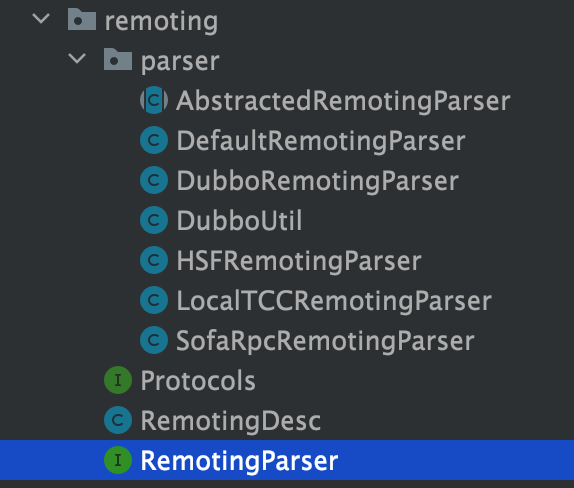
RemotingParser 接口主要有 isRemoting、isReference、isService、getServiceDesc 等方法,默认的实现为 DefaultRemotingParser,其余各自的
RPC 协议解析类都在 DefaultRemotingParser 中执行,Seata 目前已经实现了对 Dubbo、HSF、SofaRpc、LocalTCC 的 RPC 协议的解析,同时具备 SPI 可扩展性,未来欢迎大家为
Seata 提供更多的 RPC 协议解析类。
在 Seata 启动过程中,有个 GlobalTransactionScanner 注解进行扫描,会执行以下方法:
io.seata.spring.util.TCCBeanParserUtils#isTccAutoProxy
该方法目的是判断 bean 是否已被 TCC 代理,在过程中会先判断 bean 是否是一个 Remoting bean,如果是则调用 getServiceDesc 方法对 remoting bean
进行解析,同时判断如果是一个发起方,则对其进行资源注册:
io.seata.rm.tcc.remoting.parser.DefaultRemotingParser#parserRemotingServiceInfo
public RemotingDesc parserRemotingServiceInfo(Object bean,String beanName,RemotingParser remotingParser){
RemotingDesc remotingBeanDesc=remotingParser.getServiceDesc(bean,beanName);
if(remotingBeanDesc==null){
return null;
}
remotingServiceMap.put(beanName,remotingBeanDesc);
Class<?> interfaceClass=remotingBeanDesc.getInterfaceClass();
Method[]methods=interfaceClass.getMethods();
if(remotingParser.isService(bean,beanName)){
try{
//service bean, registry resource
Object targetBean=remotingBeanDesc.getTargetBean();
for(Method m:methods){
TwoPhaseBusinessAction twoPhaseBusinessAction=m.getAnnotation(TwoPhaseBusinessAction.class);
if(twoPhaseBusinessAction!=null){
TCCResource tccResource=new TCCResource();
tccResource.setActionName(twoPhaseBusinessAction.name());
tccResource.setTargetBean(targetBean);
tccResource.setPrepareMethod(m);
tccResource.setCommitMethodName(twoPhaseBusinessAction.commitMethod());
tccResource.setCommitMethod(interfaceClass.getMethod(twoPhaseBusinessAction.commitMethod(),
twoPhaseBusinessAction.commitArgsClasses()));
tccResource.setRollbackMethodName(twoPhaseBusinessAction.rollbackMethod());
tccResource.setRollbackMethod(interfaceClass.getMethod(twoPhaseBusinessAction.rollbackMethod(),
twoPhaseBusinessAction.rollbackArgsClasses()));
// set argsClasses
tccResource.setCommitArgsClasses(twoPhaseBusinessAction.commitArgsClasses());
tccResource.setRollbackArgsClasses(twoPhaseBusinessAction.rollbackArgsClasses());
// set phase two method's keys
tccResource.setPhaseTwoCommitKeys(this.getTwoPhaseArgs(tccResource.getCommitMethod(),
twoPhaseBusinessAction.commitArgsClasses()));
tccResource.setPhaseTwoRollbackKeys(this.getTwoPhaseArgs(tccResource.getRollbackMethod(),
twoPhaseBusinessAction.rollbackArgsClasses()));
//registry tcc resource
DefaultResourceManager.get().registerResource(tccResource);
}
}
}catch(Throwable t){
throw new FrameworkException(t,"parser remoting service error");
}
}
if(remotingParser.isReference(bean,beanName)){
//reference bean, TCC proxy
remotingBeanDesc.setReference(true);
}
return remotingBeanDesc;
}
以上方法,先调用解析类 getServiceDesc 方法对 remoting bean 进行解析,并将解析后的 remotingBeanDesc 放入 本地缓存 remotingServiceMap
中,同时调用解析类 isService 方法判断是否为发起方,如果是发起方,则解析 TwoPhaseBusinessAction 注解内容生成一个 TCCResource,并对其进行资源注册。
资源管理
1、资源注册
Seata TCC 模式的资源叫 TCCResource,其资源管理器叫 TCCResourceManager,前面讲过,当解析完 TCC 接口 RPC 资源后,如果是发起方,则会对其进行资源注册:
io.seata.rm.tcc.TCCResourceManager#registerResource
public void registerResource(Resource resource){
TCCResource tccResource=(TCCResource)resource;
tccResourceCache.put(tccResource.getResourceId(),tccResource);
super.registerResource(tccResource);
}
TCCResource 包含了 TCC 接口的相关信息,同时会在本地进行缓存。继续调用父类 registerResource 方法(封装了通信方法)向 TC 注册,TCC 资源的 resourceId 是
actionName,actionName 就是 @TwoParseBusinessAction 注解中的 name。
2、资源提交/回滚
io.seata.rm.tcc.TCCResourceManager#branchCommit
public BranchStatus branchCommit(BranchType branchType,String xid,long branchId,String resourceId,
String applicationData)throws TransactionException{
TCCResource tccResource=(TCCResource)tccResourceCache.get(resourceId);
if(tccResource==null){
throw new ShouldNeverHappenException(String.format("TCC resource is not exist, resourceId: %s",resourceId));
}
Object targetTCCBean=tccResource.getTargetBean();
Method commitMethod=tccResource.getCommitMethod();
if(targetTCCBean==null||commitMethod==null){
throw new ShouldNeverHappenException(String.format("TCC resource is not available, resourceId: %s",resourceId));
}
try{
//BusinessActionContext
BusinessActionContext businessActionContext=getBusinessActionContext(xid,branchId,resourceId,
applicationData);
// ... ...
ret=commitMethod.invoke(targetTCCBean,args);
// ... ...
return result?BranchStatus.PhaseTwo_Committed:BranchStatus.PhaseTwo_CommitFailed_Retryable;
}catch(Throwable t){
String msg=String.format("commit TCC resource error, resourceId: %s, xid: %s.",resourceId,xid);
LOGGER.error(msg,t);
return BranchStatus.PhaseTwo_CommitFailed_Retryable;
}
}
当 TM 决议二阶段提交,TC 会通过分支注册的的资源 ID 回调到对应参与者(即 TCC 接口发起方)服务中执行 TCC Resource 的 Confirm/Cancel 方法。
资源管理器中会根据 resourceId 在本地缓��存找到对应的 TCCResource,同时根据 xid、branchId、resourceId、applicationData 找到对应的 BusinessActionContext
上下文,执行的参数就在上下文中。最后,执行 TCCResource 中获取 commit 的方法进行二阶段提交。
二阶段回滚同理类似。
事务处理
前面讲过,如果 TCC 接口时一个调用方,则会使用 Seata TCC 代理对调用方进行拦截处理,并在处理调用真正的 RPC 方法前对分支进行注册。
执行方法io.seata.spring.util.TCCBeanParserUtils#isTccAutoProxy除了对 TCC 接口资源进行解析,还会判断 TCC 接口是否为调用方,如果是调用方则返回 true:
io.seata.spring.annotation.GlobalTransactionScanner#wrapIfNecessary

如图,当 GlobalTransactionalScanner 扫描到 TCC 接口调用方(Reference)时,会使 TccActionInterceptor 对其进行代理拦截处理,TccActionInterceptor
实现 MethodInterceptor。
在 TccActionInterceptor 中还会调用 ActionInterceptorHandler 类型执行拦截处理逻辑,事务相关处理就在 ActionInterceptorHandler#proceed 方法中:
public Object proceed(Method method,Object[]arguments,String xid,TwoPhaseBusinessAction businessAction,
Callback<Object> targetCallback)throws Throwable{
//Get action context from arguments, or create a new one and then reset to arguments
BusinessActionContext actionContext=getOrCreateActionContextAndResetToArguments(method.getParameterTypes(),arguments);
//Creating Branch Record
String branchId=doTccActionLogStore(method,arguments,businessAction,actionContext);
// ... ...
try{
// ... ...
return targetCallback.execute();
}finally{
try{
//to report business action context finally if the actionContext.getUpdated() is true
BusinessActionContextUtil.reportContext(actionContext);
}finally{
// ... ...
}
}
}
以上,在执行 TCC 接口一阶段之前,会调用 doTccActionLogStore 方法分支注册,同时还会将 TCC 相关信息比如参数放置在上下文,上面讲的资源提交/回滚就会用到这个上下文。
如何控制异常
在 TCC 模型执行的过程中,还可能会出现各种异常,其中最为常见的有空回滚、幂等、悬挂等。下面我讲下 Seata 是如何处理这三种异常的。
如何处理空回滚
什么是空回滚?
空回滚指的是在一个分布式事务中,在没有调用参与方的 Try 方法的情况下,TM 驱动二阶段回滚调用了参与方的 Cancel 方法。
那么空回滚是如何产生的呢?
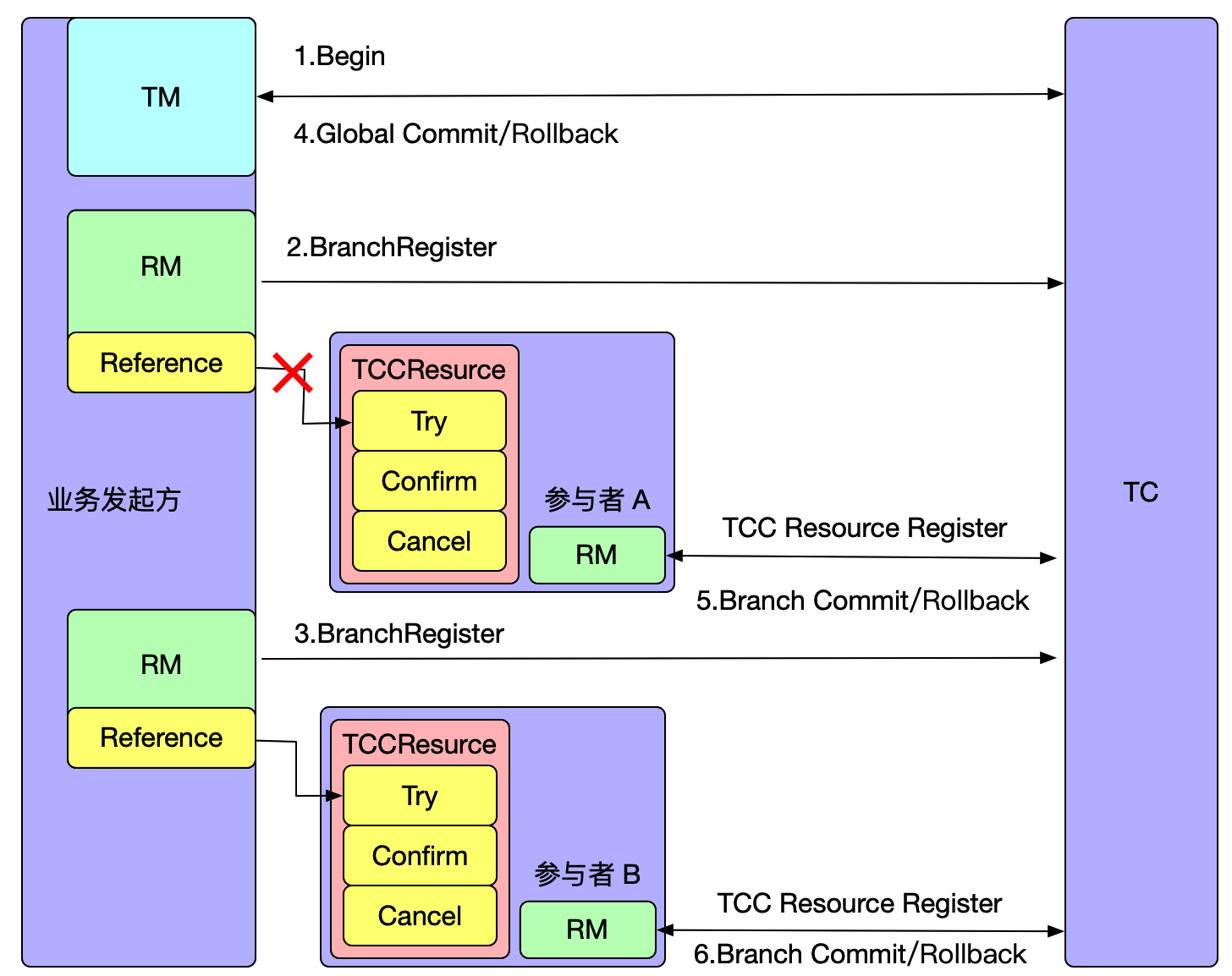
如上图所示,全局事务开启后,参与者 A 分支注册完成之后会执行参与者一阶段 RPC 方法,如果此时参与者 A 所在的机器发生宕机,网络异常,都会造成 RPC 调用失败,即参与者 A 一阶段方法未成功执行,但是此时全局事务已经开启,Seata 必须要推进到终态,在全局事务回滚时会调用参与者 A 的 Cancel 方法,从而造成空回滚。
要想防止空回滚,那么必须在 Cancel 方法中识别这是一个空回滚,Seata 是如何做的呢?
Seata 的做法是新增一个 TCC 事务控制表,包含事务的 XID 和 BranchID 信息,在 Try 方法执行时插入一条记录,表示一阶段执行了,执行 Cancel 方法时读取这条记录,如果记录不存在,说明 Try 方法没��有执行。
如何处理幂等
幂等问题指的是 TC 重复进行二阶段提交,因此 Confirm/Cancel 接口需要支持幂等处理,即不会产生资源重复提交或者重复释放。
那么幂等问题是如何产生的呢?
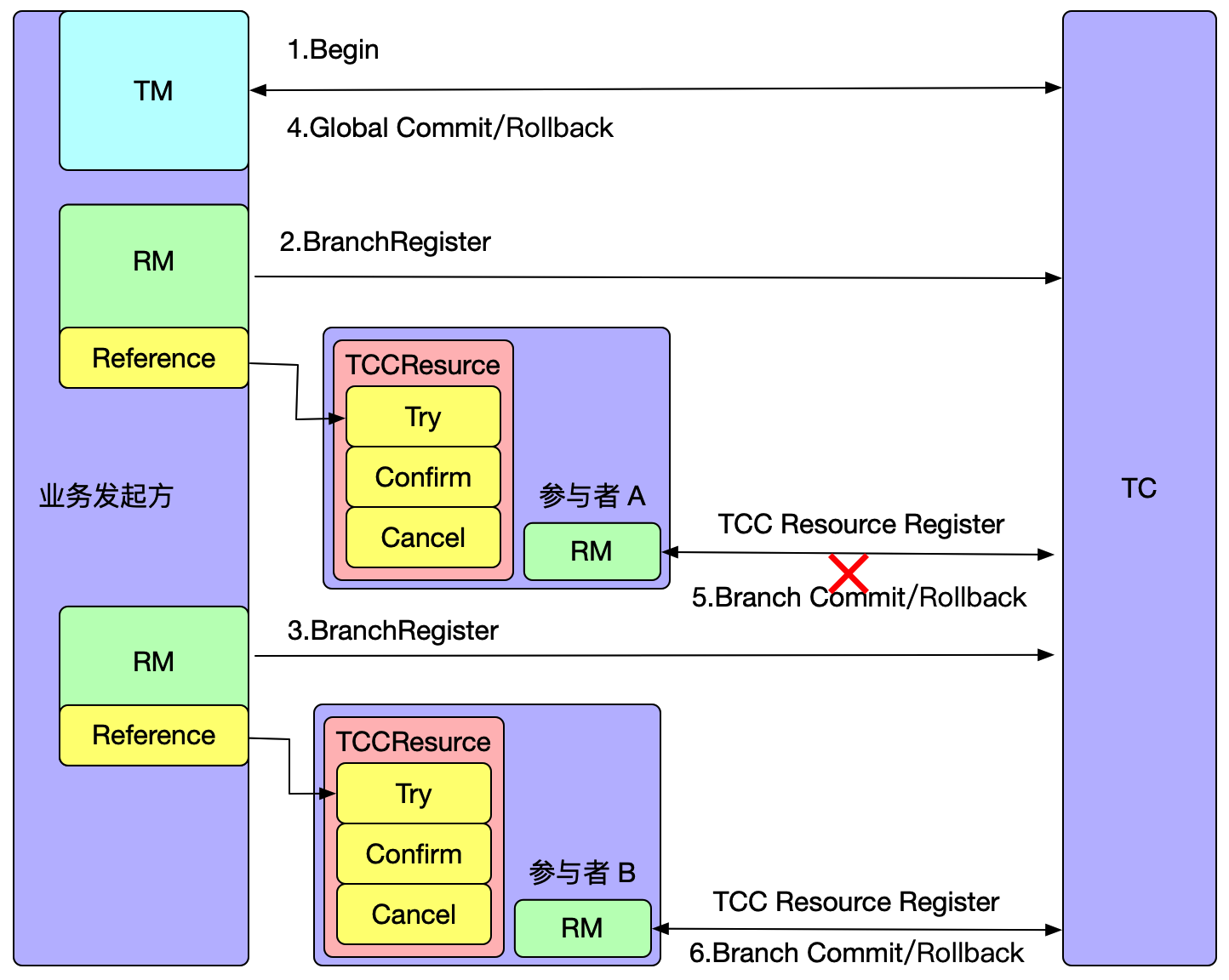
如上图所示,参与者 A 执行完二阶段之后,由于网络抖动或者宕机问题,会造成 TC 收不到参与者 A 执行二阶段的返回结果,TC 会重复发起调用,直到二阶段执行结果成功。
Seata 是如何处理幂等问题的呢?
同样的也是在 TCC 事务控制表中增加一个记录状态的字段 status,该字段有 3 个值,分别为:
- tried:1
- committed:2
- rollbacked:3
二阶段 Confirm/Cancel 方法执行后,将状态改为 committed 或 rollbacked 状态。当重复调用二阶段 Confirm/Cancel 方法时,判断事务状态即可解决幂等问题。
如何处理悬挂
悬挂指的是二阶段 Cancel 方法比 一阶段 Try 方法优先执行,由于允许空回滚的原因,在执行完二阶段 Cancel 方法之后直接空回滚返回成功,此时全局事务已结束,但是由于 Try 方法随后执行,这就会造成一阶段 Try 方法预留的资源永远无法提交和释放了。
那么悬挂是如何产生的呢?
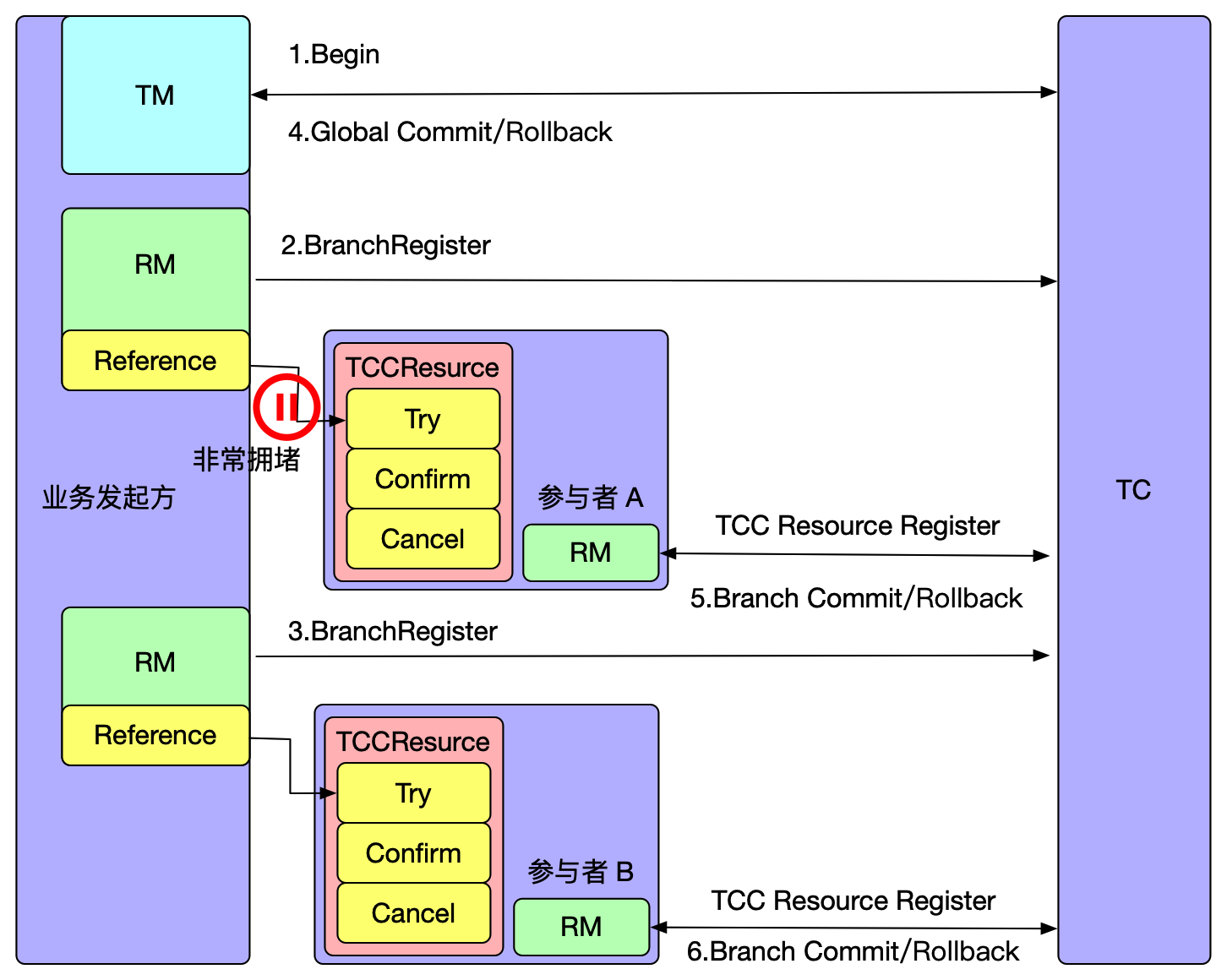
如上图所示,在执行参与者 A 的一阶段 Try 方法时,出现网路拥堵,由于 Seata 全局事务有��超时限制,执行 Try 方法超时后,TM 决议全局回滚,回滚完成后如果此时 RPC 请求才到达参与者 A,执行 Try 方法进行资源预留,从而造成悬挂。
Seata 是怎么处理悬挂的呢?
在 TCC 事务控制表记录状态的字段 status 中增加一个状态:
- suspended:4
当执行二阶段 Cancel 方法时,如果发现 TCC 事务控制表没有相关记录,说明二阶段 Cancel 方法优先一阶段 Try 方法执行,因此插入一条 status=4 状态的记录,当一阶段 Try 方法后面执行时,判断 status=4 ,则说明有二阶段 Cancel 已执行,并返回 false 以阻止一阶段 Try 方法执行成功。
作者简介
张乘辉,目前就职于蚂蚁集团,热爱分享技术,微信公众号「后端进阶」作者,技术博客(https://objcoding.com/)博主,GitHub ID:objcoding。





 改成:
改成: